
What Is Ontology-Grounded Retrieval-Augmented Generation?
Discover how a semantic model of meaning makes AI answers more accurate

Technical writers keep hearing that Retrieval-Augmented Generation (RAG) makes AI answers more accurate because it grounds responses in real content. That is true — but it’s only part of the story.
RAG is often described as “LLMs plus search.” That description is incomplete — and for technical writers, potentially misleading.
Ontology-grounded RAG is a more advanced approach that anchors AI responses not just in retrieved content, but in an explicit semantic model of meaning. It ensures that AI systems retrieve and generate answers based on what things are, how they relate, and under what conditions information is valid.
If AI is becoming the public voice of our products, ontology-grounded RAG is how we keep that voice accurate, consistent, and accountable.
If you work with structured content, metadata, or controlled vocabularies, this topic is very much in your lane.
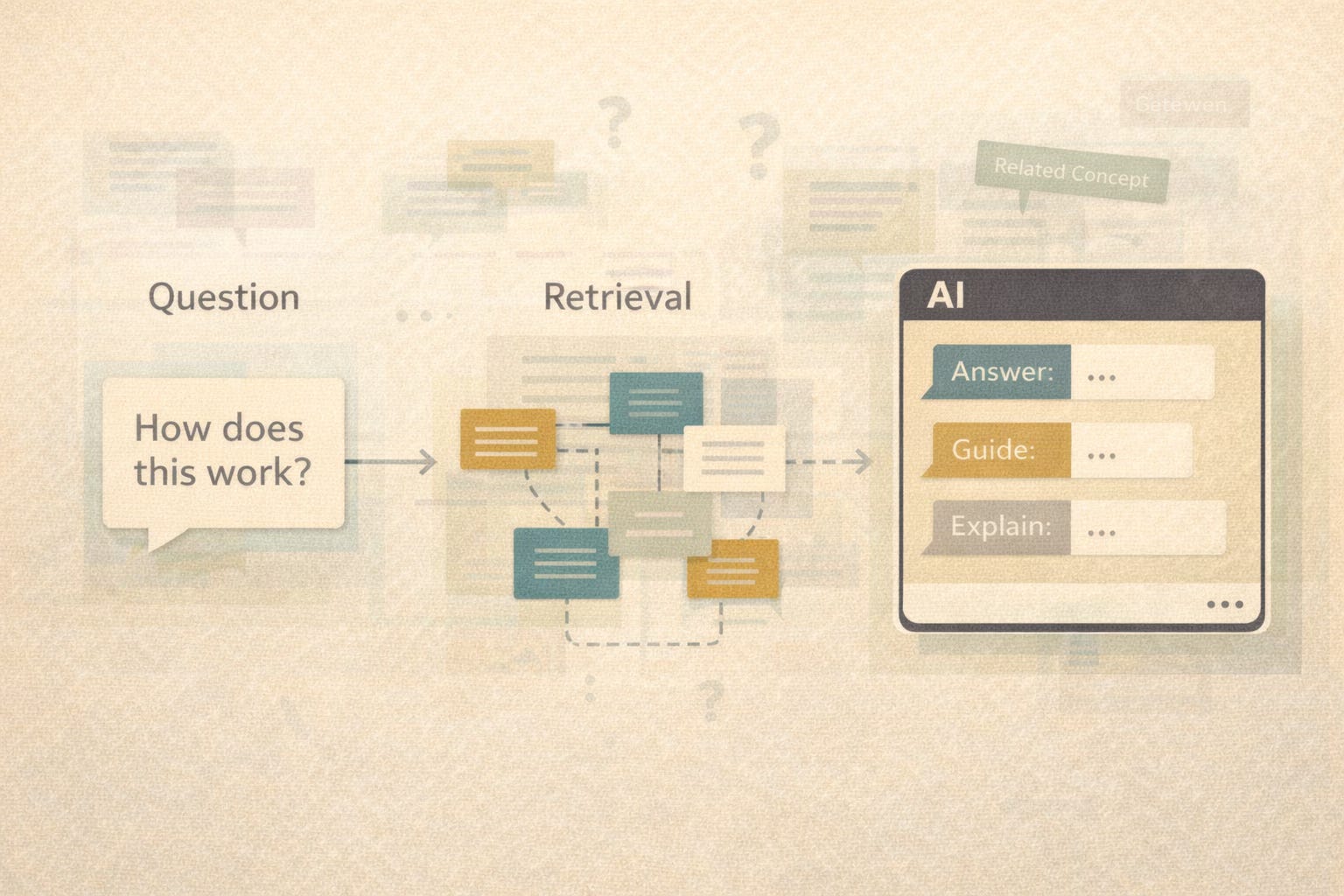
Why Standard RAG Is Insufficient
Standard RAG works like this:
A user asks a question
The system retrieves relevant chunks of content (documents, passages, topics)
An LLM generates an answer using that retrieved text as context
This improves accuracy over “pure” generative AI, but it still has limits:
Retrieval is often keyword- or embedding-based, not meaning-based
Related concepts may not be retrieved if the wording differs
The model may mix incompatible concepts or versions
There is little accountability for why something was retrieved
What Changes With Ontology-Grounded RAG?
Ontology-grounded RAG adds a formal knowledge model — an ontology — between your content and the AI.
An ontology explicitly defines:
Concepts (products, features, tasks, warnings, roles, versions)
Relationships (depends on, replaces, applies to, incompatible with)
Constraints (this feature only applies to this product line or version)
Synonyms and preferred terminology
Instead of asking, “Which chunks are similar to this question?” the system can ask:
“Which concepts are relevant, and what content is authoritative for those concepts in this context?”
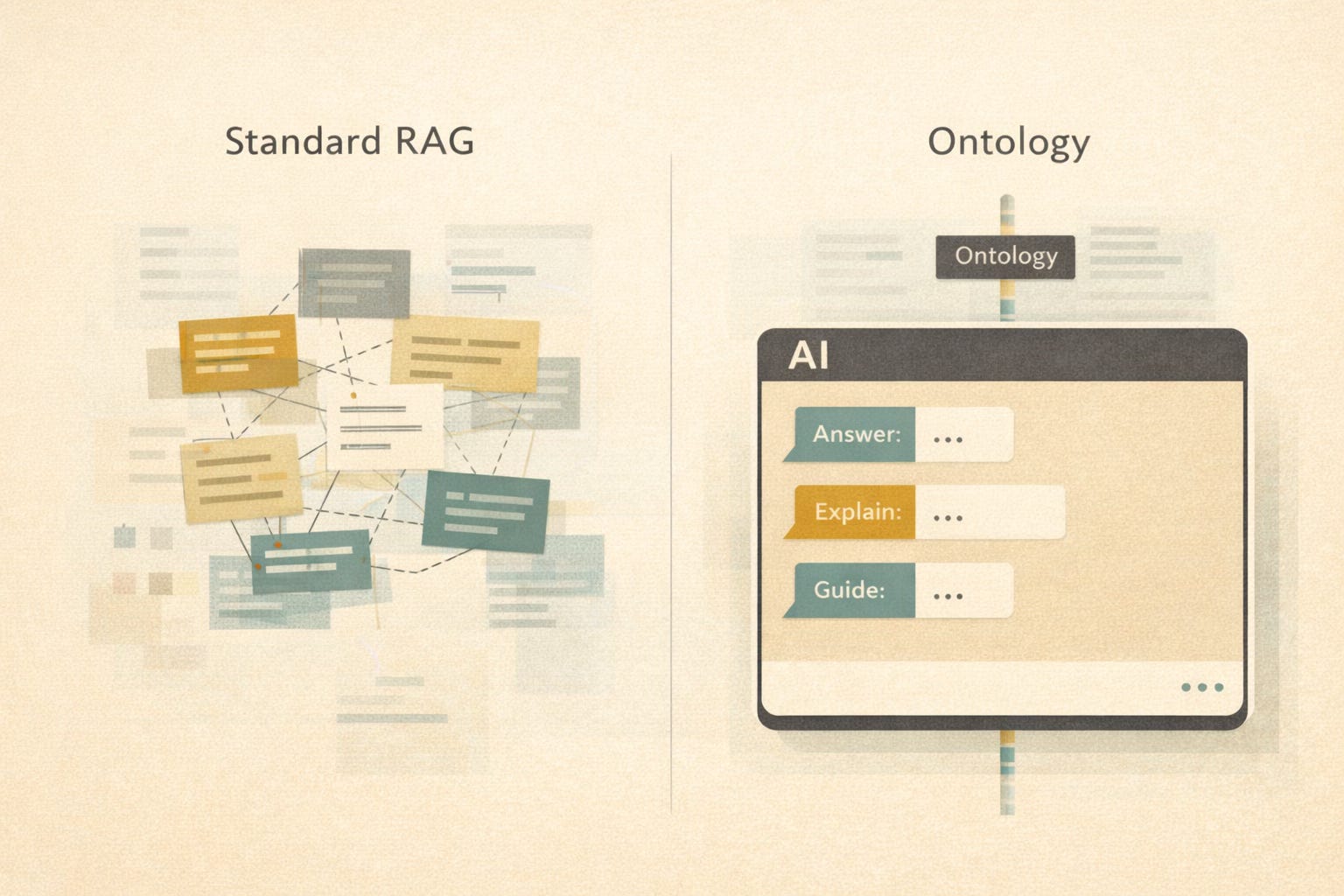
Ontology-Grounded RAG In Plain Language
Here is the simplest way to think about it:
Standard RAG retrieves text that looks relevant
Ontology-grounded RAG retrieves content that means the right thing
The ontology acts as a semantic spine that keeps AI answers aligned with reality.
Why technical writers should care
Ontology-grounded RAG rewards practices technical writers already value:
1. Clear concept definitions
If we cannot clearly define what a “feature,” “module,” or “service” is, our AI cannot either.
👉🏾 Ontologies force clarity.
2. Structured, modular content
Topic-based authoring (DITA, component content) maps naturally to ontological concepts.
👉🏾 Long narrative documents do not.
See also: What is the Darwin Information Typing Architecture (DITA)?
3. Metadata that actually matters
In ontology-grounded systems, metadata is not decorative. It drives:
Retrieval
Filtering
Disambiguation
Answer justification
👉🏾 This turns metadata work into high-leverage labor.
4. Fewer hallucinations, better trust
When an ontology enforces relationships and constraints, the AI cannot easily:
Combine incompatible product features
Ignore version boundaries
Answer outside its authority scope
👉🏾 This is how you move from plausible answers to defensible answers.
How Ontology-Grounded RAG Typically Works
User asks a question
“How do I configure authentication for Product X?”
Ontology interprets intent
Product = Product X
Concept = Authentication
Task = Configuration
Version constraints apply
Retriever queries by meaning
Not just “authentication” text
Only content linked to the correct product, version, and task type
LLM generates the response
Using only semantically valid, authorized content
Often with traceable sources
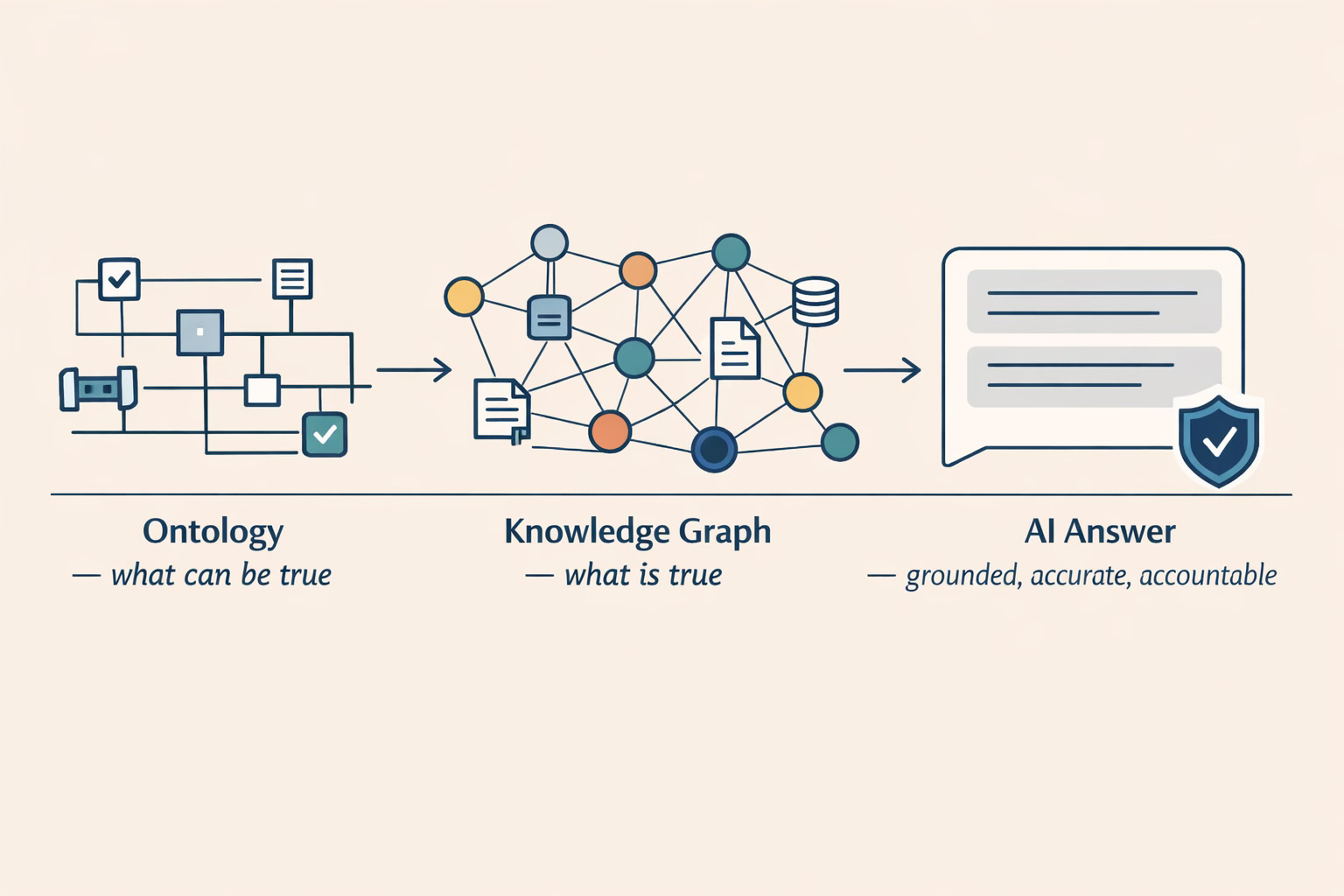
How This Differs From “Just Adding A Knowledge Graph”
A knowledge graph stores facts and relationships.
An ontology defines the rules of meaning those facts must obey.
Ontology-grounded RAG uses both:
The ontology defines what can be true
The knowledge graph and content provide what is true
This distinction matters when accuracy, safety, or compliance is on the line.
Where This Is Already Showing Up
You will see ontology-grounded RAG emerging in:
Regulated industries (healthcare, finance, aerospace)
Complex product ecosystems (platforms, APIs, product families)
Enterprise documentation systems integrating AI assistants
AI copilots that must explain why an answer is correct
This approach aligns closely with long-standing semantic web standards such as RDF, OWL, and SKOS.
See also: Semantic Web standards
The Uncomfortable Truth (And Opportunity)
Ontology-grounded RAG exposes weak content foundations fast.
If your content has:
Inconsistent terminology
Unclear product boundaries
Missing metadata
Version ambiguity
AI will surface those flaws immediately.
For technical writers, that is not a threat. It is leverage.
How This Maps Directly To DITA And Component Content Workflows
One reason the OG-RAG research should feel familiar to experienced technical writers is that it mirrors how structured documentation systems already work — when they are used as intended.
Ontology-grounded RAG does not introduce a new way of thinking. It validates an existing one.
Concept Modeling = DITA Concept Topics
In OG-RAG, the ontology defines what things are and how they relate.
In DITA, this role is already played by:
Concept topics (“What is this?”)
Stable terminology
Reusable definitions
Explicit scoping of meaning
When concept topics are written clearly and consistently, they provide exactly the kind of semantic grounding OG-RAG depends on. The AI does not have to infer meaning from prose — it can retrieve it directly.
OG-RAG succeeds because it preserves relationships:
prerequisites
dependencies
applicability
cause-and-effect
In a DITA or CCMS environment, those relationships already exist as:
maps and submaps
linking and relationship tables
metadata such as product, platform, version, role, or audience
When this structure is present and governed, our AI systems can retrieve the right facts for the right context, instead of nearby text that merely sounds like it might be related.
This is the difference between “text similarity” and semantic relevance
In plain terms:
Well-written concept topics become the ontology’s vocabulary.
Minimal Context Selection = Modular Topics With Intent
The research shows that smaller, well-scoped units outperform large, comprehensive pages.
That aligns directly with:
DITA topic modularity
Task topics with a single goal
Reference topics with a single scope
Clear intent per topic
When content units have defined purpose, AI systems can assemble precise answers without dragging in unrelated material “just in case.”
In other words:
Topic discipline is context engineering.
The Takeaway For Tech Writers
Ontology-grounded RAG reframes the role of documentation teams from content producers to knowledge modelers and meaning stewards. Writers who understand structure, semantics, and intent will shape how AI speaks for their products.
Those who do not will inherit whatever the model guesses.
And guessing is exactly what ontology-grounded RAG is designed to eliminate.🤠
Scott, do you have any examples of OG-RAG systems that make use of metadata or that consult an ontology?
Hi Scott, great article on a very relevant topic. As a terminology geek, I would add that terminology fulfils many of these tasks already, and can at the same time be a great starting point for building taxonomies or ontologies. I just published a blog article on our "TAG" approach - Terminology-Augmented Generation, which goes very much in line with what you write here: https://kaleidoscope.at/en/blog/better-ai-results-through-tag-and-mcp/ . Let me know what you think!