
What is the Darwin Information Typing Architecture (DITA)?
DITA helps tech writers break docs into small, purposeful units — called topics — that can be reused, rearranged, and published consistently across many outputs

The Darwin Information Typing Architecture (DITA) is an XML-based standard for creating, managing, and publishing technical documentation as modular, reusable content. OASIS maintains the DITA standard and provides access to information about its usage.
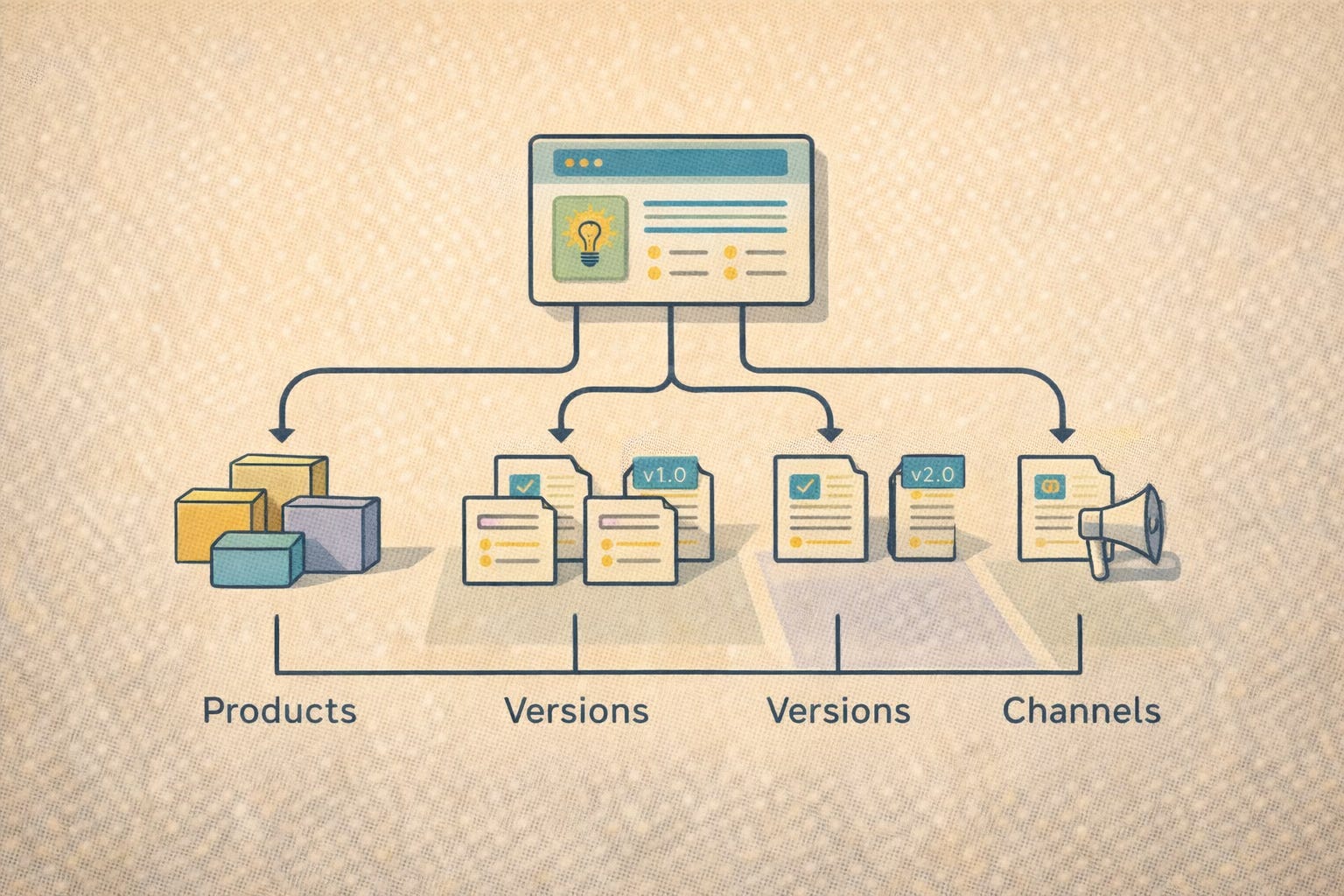
DITA matters because it forces clarity and discipline at the point of creation. Each topic has a single intent — concept, task, or reference — which makes content easier for people to scan and easier for machines to process. That structure enables reliable reuse, reduces duplication, and improves consistency across products, versions, and channels. Writers stop rewriting the same explanation five times and start managing one trusted source of truth.
DITA is also built for scale and change. Its specialization and inheritance model lets organizations extend the standard without breaking it, while maps assemble topics into many deliverables from the same content set. The result is faster updates, cleaner localization workflows, and publishing pipelines that can target PDFs, HTML, portals, and help systems from the same content base.
Finally, DITA future-proofs documentation for AI-driven delivery. Because topics are semantically typed and structurally consistent, search engines, chat systems, and retrieval-augmented generation pipelines can identify intent and return precise answers instead of dumping entire pages. In an era where documentation feeds intelligent systems, DITA gives technical writers a way to make content both human-readable and machine-ready.
DITA content is best managed in a component content management system designed specifically to help technical writers create, manage, and deliver documentation to the humans and machines that require it. 🤠