
Shifting Roles - From Content Professionals to Ontologists
Mark Wentowski demystifies how LLMs are shifting content professionals into ontologists who structure and verify knowledge for both humans and intelligent agents

Content pros are encountering new challenges in the Large Language Model (LLM) and agent era, highlighting the need for a different approach to authoring tools. Trust in LLM-generated content is the next hurdle, and transparency about the LLM’s information sources is needed.
Underscoring this, LLMs’ answers are only as good as the source content, which, in most cases, will be proprietary and will not be part of an LLM’s general intelligence about non-proprietary sources like blog posts. So the LLM needs to be an expert on your product, and someone needs to author this content, either with or without AI assistance.
The Current Paradigm
Right now, most authoring is aimed at publishing content for people. While chatbots can use this information to answer questions, the content isn’t designed with agents in mind. Humans remain an important audience, but we also need source content that works well for both LLMs and people. Similar to how web design shifted to a “mobile-first” approach, we could move to an “agent-first” design for documentation. This doesn’t mean humans are less important; it just means that focusing on agents is more challenging but will still meet human needs.
Related: AI-Powered Authoring: Will Machines Replace Technical Writers?
The Shifting Role of Authors
Authors should always retain the freedom to “just type something” in an editor, but moving forward, a bit more discipline will be required. As LLMs and agents become more adept at generating content (especially when supplied with verifiable facts) the role of the human author is evolving. Their primary responsibility will shift toward establishing a foundation for content verification. This includes building taxonomies, which might be generated automatically from source material and then refined by the author, or created manually for maximum control by a discerning analyst. Additionally, authors will help map product concepts to ontologies to enable deeper and more meaningful interconnections.
Taxonomies: How to Find Things
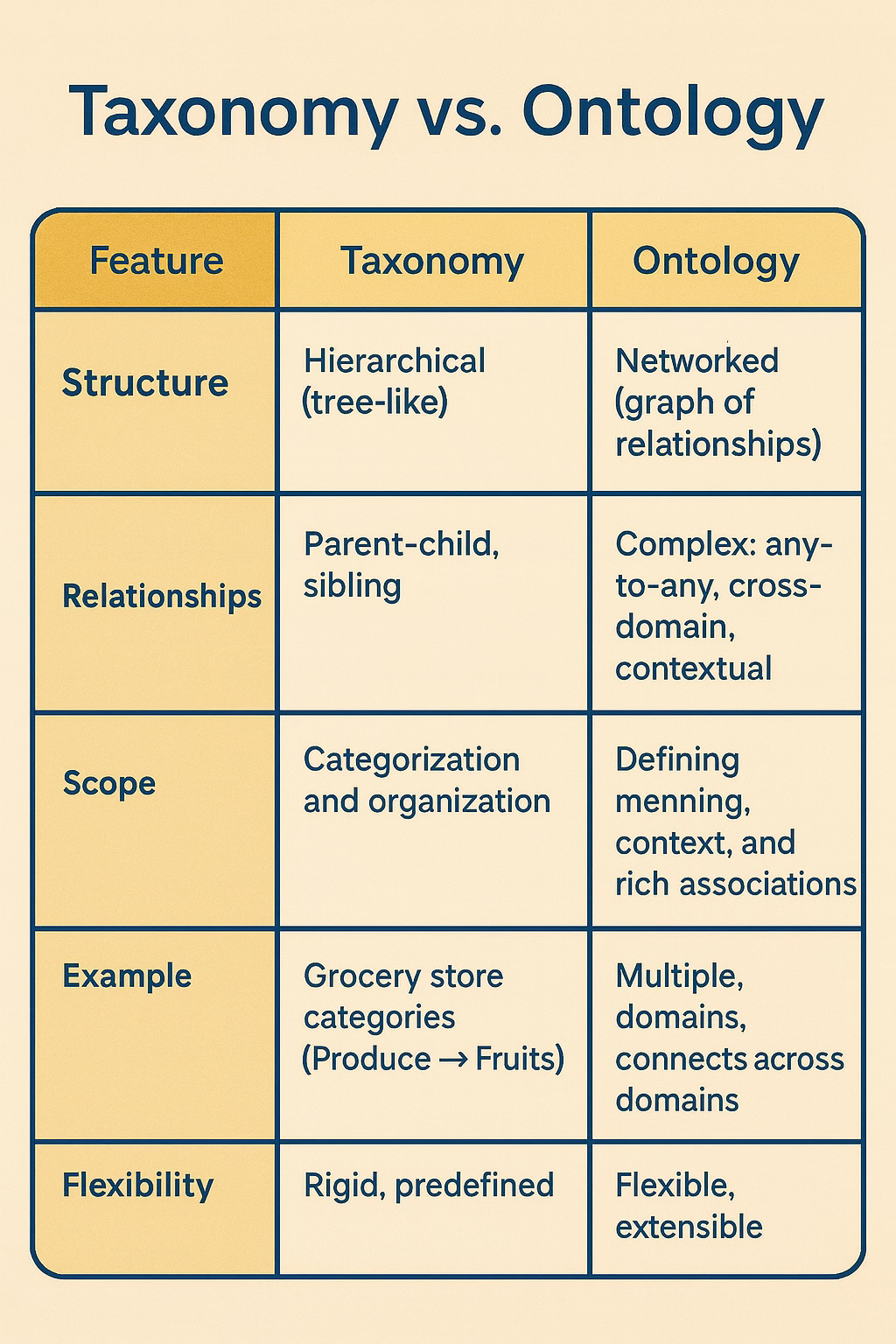
A taxonomy organizes items into categories within a clear hierarchical structure, much like a tree with branches and sub-branches. Each item is assigned to a category, making it easier to find by moving from broad groupings to more specific ones. These relationships typically take the form of parent-child or sibling connections.
We see taxonomies every day—for example, website navigation menus that let us drill down from broad categories to more specific items.
Why do taxonomies matter?
According to Earley Information Science:
Related: What Is the Difference between Taxonomy and Ontology?
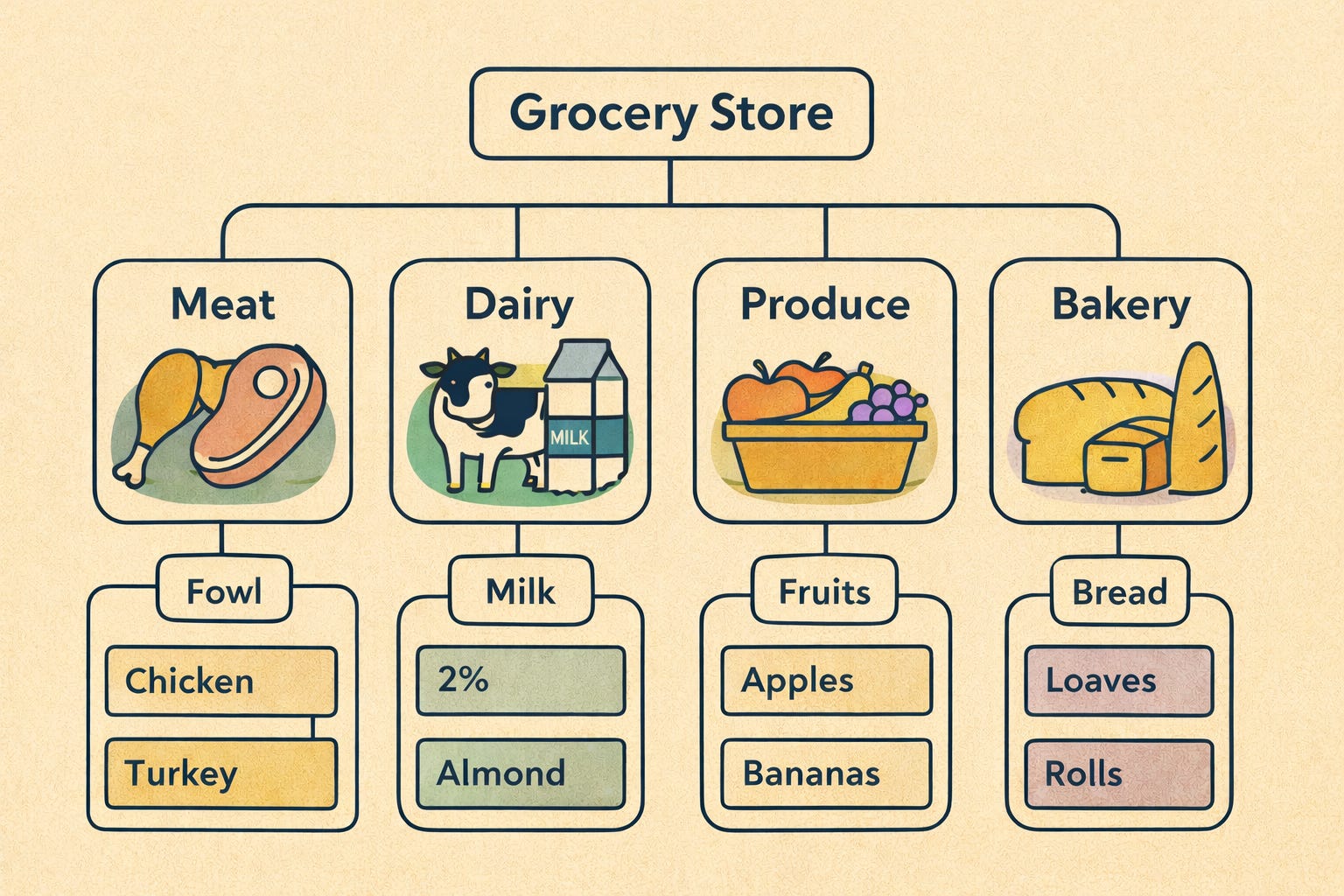
Consider a grocery store: its organization is a practical example of a taxonomy in action. Products are grouped into clear categories:
Produce → Fruits → apples and bananas
Dairy → milk and yogurt
Meat → Chicken and beef
Bakery → Bread and cookies
This system shows you exactly where to find items. It’s hierarchical and structured, so you won’t find yogurt in the cereal aisle. The main benefit is efficient organization and quick retrieval.
If the grocery store had a website, its taxonomy would guide how you browse and filter products online. The site’s navigation and structure often match the store’s taxonomy, helping users find what they need.
For writers, setting up a taxonomy gives a clear framework for structuring content, building page hierarchies, and making internal tables of contents. Rather than starting from scratch, a good taxonomy gives you an organized starting point for creating content.
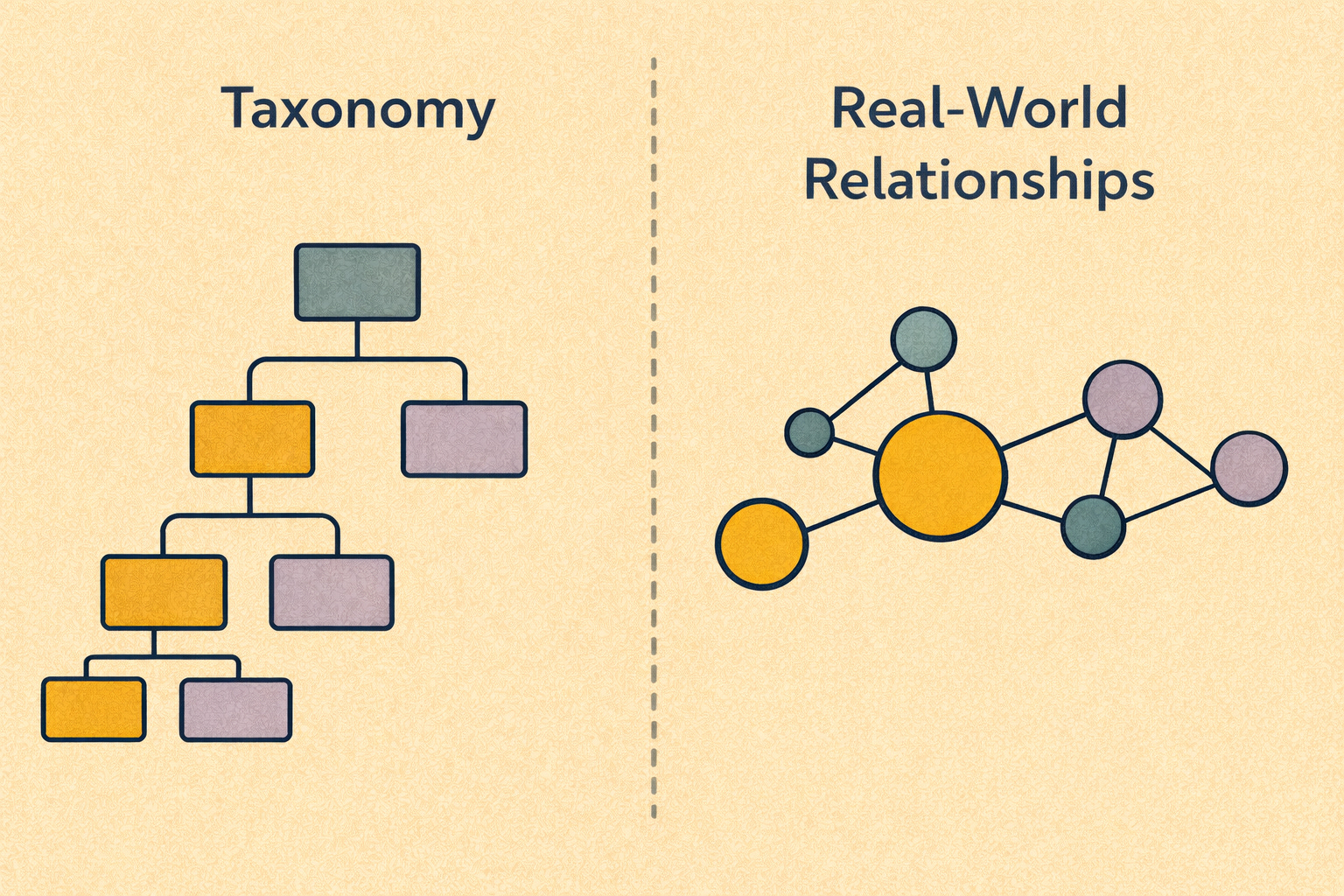
Limitations of Taxonomies
Taxonomies are great for organizing information, but they have some limits. Their structure is strictly hierarchical, grouping items as parent, child, or sibling within one domain. This makes it hard to show more complex connections, such as links between items in different taxonomies or across domains.
Taxonomies define categories within a single domain. In this case, the product domain. A taxonomy can’t connect to other domains on its own. That’s a job for an ontology. —> Source: Earley Information Science
Another issue is that taxonomy categories often serve as simple organizational “tags,” rather than formal classes. Because of this, taxonomies can label and sort items, but they don’t capture the richer, more detailed relationships that ontologies or class-based systems can show.
Related: Categories Or Tagging? Differences In Taxonomy And Information Architecture
Ontologies: Going Beyond Hierarchies
Ontologies do more than taxonomies by capturing complex, meaningful relationships between entities, not just simple hierarchies.
In an ontology, you define classes (abstract types) and individuals (instances), which lets you map how things connect, even across different taxonomies or domains. Unlike taxonomy categories, ontology classes help you make logical inferences about relationships and properties.
Related: LLM Reasoning vs. Logical Ontology Graph Reasoning: A Comparative Analysis
Let’s take the grocery store example further. A pastry chef making desserts for guests with allergies and dietary needs must not only identify ingredients (taxonomy) but also understand relationships, such as which ingredients can be swapped or which combinations meet certain requirements (ontology).
For example:
Tapioca flour is gluten-free and creates crisp shells
Agar-agar replaces gelatin for setting
Yuzu pairs with vanilla and reduces sugar
Meringue adds crunch but requires eggs (an allergy risk)
Oat crumble adds texture but may contain cross-contamination
Maltitol is a sugar substitute, but it can affect digestion
These relationships are about function and context, not hierarchy.
Ontologies help the chef answer questions like:
What ingredients can substitute for others?
Which combinations satisfy dietary constraints?
What must be avoided together?
What achieves the desired result?
In short, ontologies add meaning and context, giving you different ways to understand or use the same item. You can use ontologies to connect your internal concepts with external standards and trusted resources.
This mapping is especially useful for setting up sources of truth and for verification. For example, linking your product ontology to an industry standard such as Financial Industry Business Ontology (FIBO) lets agents verify your content against trusted sources.
Agents can also use well-established external documentation or published books as extra references. Importantly, people still play a key role: agents can suggest changes, but content professionals make the final decisions.
In API documentation, ontologies can turn resources into canonical entities and link them to external standards, enriching documentation and ensuring verifiability.
Taxonomy vs. Ontology
Let’s review the difference between a taxonomy and an ontology.
Structuring Content for the Agent Era
Once taxonomies and ontologies are in place, the authoring process can go beyond separate markdown files and freeform text. Now, content should be organized into independent, self-contained knowledge chunks, each with its own metadata and structured data. This way, information is both easy for people to read and for machines to use, supporting agents and automation.
Related: Understanding When to Use Structured Content Authoring
A key idea from “linked data” is that structured data and prose should match for every knowledge chunk. This makes content easier to verify and find, and helps meet standards like those Google uses for web content. While this was hard before, having taxonomies and ontologies makes it much easier.

Modern authoring tools should make it seamless to express new relationships between concepts, eliminating the need for manual markup. By enabling authors and agents to consistently contribute prose, the system can automatically generate corresponding structured data, freeing users from additional tagging.
This knowledge-chunk model also improves tracking and maintenance. Each chunk can be updated, reviewed, and audited individually, making it easier to monitor content freshness and accuracy.
It’s important to balance structure with a good authoring experience. Tools that are too rigid can limit creativity, while unstructured methods don’t offer the control and verification agents need. By using standards like schema.org, the tool can automatically generate structured data for each chunk, link it to the appropriate entities, and eliminate the need for manual schema markup.
The Bleeding Edge: Executable Content
This brings a big change: content becomes executable. Structured data lets scripts or agents take actions, such as making API calls or testing UI workflows, directly from the documentation. Now, content is both actionable for machines and easy for people to read, closing the gap between automation and usability.
Testing also improves. Instead of writing separate test cases, the structured data in the content defines the process, the required entities, and the steps to follow. This reduces duplication and keeps documentation and verification in sync.
For content that isn’t executable, taxonomies and ontologies help verify it through categories and relationships. This keeps the knowledge base accurate and consistent. It’s important to keep entities stable; once they’re defined, they anchor the content and help keep it reliable.
Charting a Path Forward
As the LLM and agent era changes how we create and use information, content professionals face new challenges and opportunities. Shifting from static, human-focused documentation to dynamic, agent-ready knowledge means rethinking our tools, processes, and mindset. By using taxonomies, ontologies, and structured knowledge chunks, we improve verifiability and discoverability, and set the stage for content that is both executable and adaptable.
This change isn’t about replacing human creativity with automation. It’s about boosting our ability to curate, verify, and connect information for both people and smart systems. The road ahead will need ongoing testing, teamwork, and improvement. By adopting these ideas now, we can keep our content trustworthy, relevant, and ready for the future.
About Mark Wentowski
Mark Wentowski is an API documentation specialist and senior technical writer with more than twelve years of experience helping SaaS companies and global development teams explain complex software to technical audiences. He focuses on developer-to-developer content for web services, APIs, libraries, and data-driven products, producing conceptual guides, configuration and deployment instructions, tutorials, references, walkthroughs, sample apps, and best-practice documentation.
His work spans the full documentation lifecycle—from research, content creation, and editorial review to publication, hosting, and long-term maintenance. Mark brings deep expertise in modern documentation tooling and implementation, including Redocly, ReadMe, Document360, Stoplight, and Gatsby JS, along with strong proficiency in Docs-as-Code workflows, Git-based collaboration, static site generators, and Markdown/HTML migrations.
He applies a modern, user-centered approach grounded in usability testing, automation, DevOps thinking, and scalable content architecture. Mark also creates diagrams, videos, and GIFs that reinforce technical concepts and improve the developer experience.