
How Technical Writers Can Make AI Systems That Use Product Documentation Trustworthy

AI systems now answer customer questions, explain features, and guide users of an increasing variety of products and services through tasks they need to complete.
In many organizations, they do this instead of sending people to the documentation.
Sometimes they do it without ever showing the customer the documentation at all.

This means our technical documentation has quietly stopped being reading material and started a new career as knowledge infrastructure. It is now the raw material from which AI systems assemble confident, well-phrased answers — whether those answers are spot-on or otherwise wildly incorrect.
Recent research (👈🏽 PDF) from EMNLP 2025 Conference on Empirical Methods in Natural Language Processing explains why so many of these systems sound smart while being wrong, and why fixing the problem has less to do with “better AI” and more to do with how documentation is structured.
Let’s talk about what the research found (and why tech writers are holding the keys to AI success, whether they asked for them or not).

First, Let’s Be Very Clear About What This Is Not
This is not about documentation of AI products.
This is about AI systems that:
Answer questions using your documentation
Generate explanations based on your docs
Power chatbots, copilots, and AI search (both standalone and embedded in apps and products)
Cheerfully speak on behalf of your product at 2 a.m.
In these systems, documentation is no longer a helpful companion. It is the authority. And if it is vague, inconsistent, or poorly structured, the AI will not hesitate to improvise — politely, fluently, and with great confidence.
The Real Problem (Spoiler: It’s Not the AI)
Most AI systems that use documentation rely on something called Retrieval-Augmented Generation, or RAG. The idea is simple and sounds reasonable enough:
Break docs into chunks
Turn chunks into vectors
Retrieve “similar” text
Ask the AI to answer
The problem is that this treats documentation like a bag of words someone spilled on the floor.
See also: The Problem with Traditional RAG Models
According to the research, this approach reliably produces:
Hallucinated steps
Mixed product versions
Feature explanations that never existed
Confident contradictions
Answers that cannot explain where they came from
This is not because the AI is careless. It is because similar text is not the same thing as relevant knowledge.
What the Research Proposes Instead
The paper introduces Ontology-Grounded Retrieval-Augmented Generation, or OG-RAG.
OG-RAG does something radical: it assumes your documentation actually means something.
Instead of asking:
“Which chunks look kind of like this question?”
It asks:
“Which concepts, facts, and relationships are required to answer this correctly?”
To do that, OG-RAG uses:
Ontologies to define what things are
Relationships to show how those things connect
Minimal context selection so the AI is not buried alive in irrelevant text
The AI gets less information, but it gets better information, which turns out to matter.
What Happened When Researchers Put This Approach To Work?
The results were not subtle.
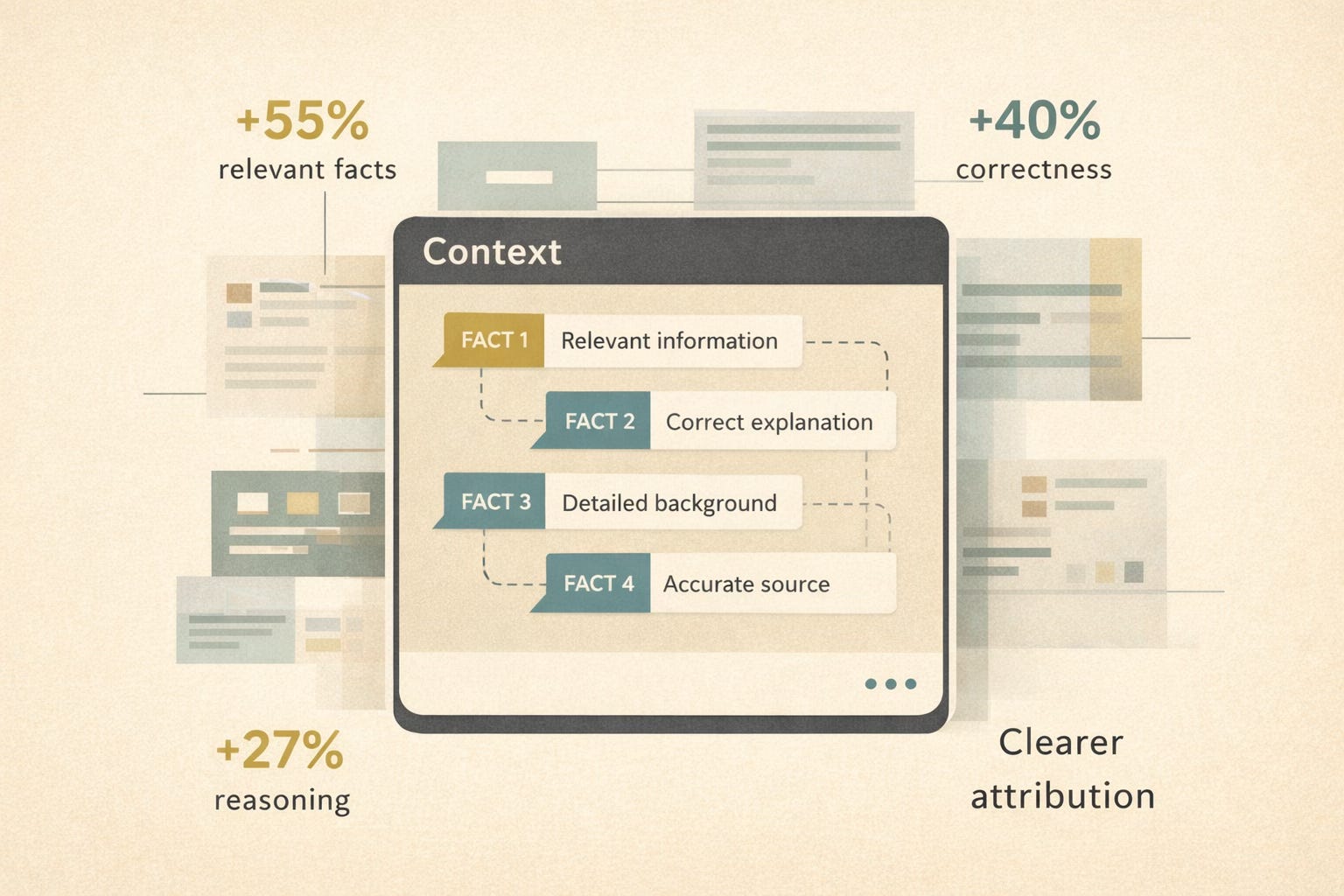
Compared to standard RAG systems, OG-RAG produced:
About 55% better recall of relevant facts
Roughly 40% higher answer correctness
27% improvement in fact-based reasoning
Faster, clearer attribution to source material
👉🏾 In plain English: the AI stopped guessing so much, contradicted itself less, and became easier to fact-check; three qualities we usually associate with “trustworthy” and rarely associate with chatbots.
Why This Should Feel Uncomfortably Familiar to Technical Writers
The research quietly confirms a truth tech writers have been explaining to management for years:
Accuracy is not a tone. It is a structure.
OG-RAG works because it assumes:
Concepts have names and definitions
Relationships matter
Content has purpose
Knowledge is modeled, not sprayed across pages
In other words, it works because someone cared enough to invest the needed time, energy and resources. That someone is usually a technical writer — when they are allowed to do their job properly.
What Actually Makes AI Systems Trustworthy
Based on the research, these four documentation qualities make the difference.
Explicit Concept Modeling
AI systems perform better when documentation treats:
Features
Components
Tasks
Constraints
Versions
as actual concepts, not casual mentions scattered across prose like breadcrumbs.
If your docs cannot decide what a thing is called, the AI will pick something for you. You probably (perhaps, definitely) will not like its choice.
Relationship-Aware Documentation
OG-RAG preserves relationships such as:
Feature → prerequisite
Task → outcome
Component → dependency
Version → applicability
Flat documentation quietly erases these relationships. Structured documentation keeps them visible and usable.

Minimal, Purpose-Driven Content Units
The research confirms what experienced writers already know: more content does not mean better answers.
Clear scope, modular topics, and defined intent beat “comprehensive” pages every time; especially when AI is involved.
See also: 10 Ways Topic-Based Authoring Changes Your Workflow
Traceability and Accountability
OG-RAG improves attribution by grounding answers in identifiable facts.
This matters if:
Your product is regulated
Your customers are enterprises
Your support team wants to sleep at night
If an AI answer cannot point back to authoritative documentation, it is not trustworthy.
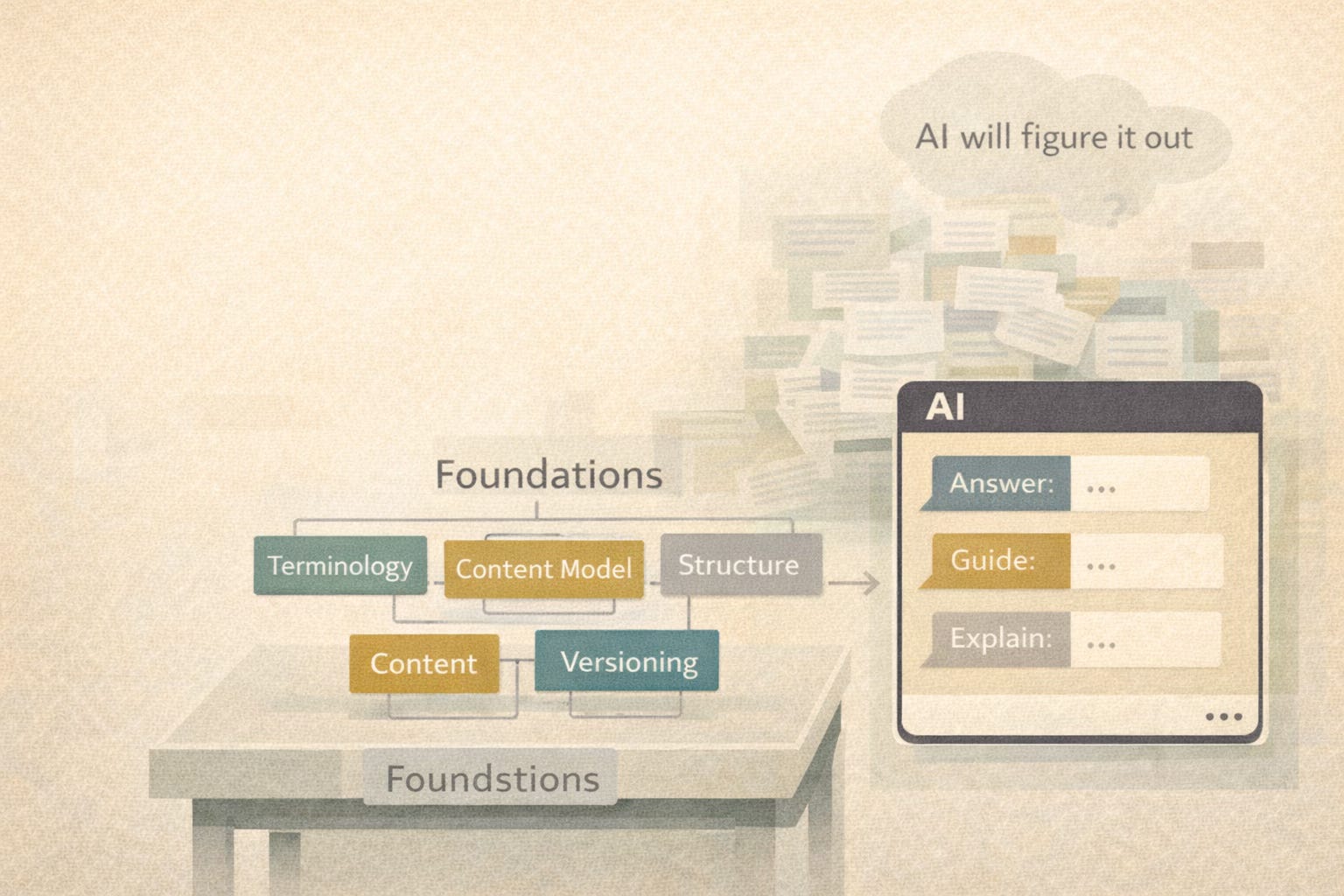
What Tech Docs Teams Can Do Without Rebuilding the World
You do not need to implement OG-RAG tomorrow.
You do need to stop assuming AI will “figure it out.” ‼️ > Spoiler: It won’t.
Ask, instead:
Does our AI rely on similarity search or structured knowledge?
Can it distinguish concepts from examples?
Can it explain which facts support an answer?
Does it understand relationships—or just proximity?
Then invest in the unglamorous work that actually pays off:
Terminology governance
Content modeling
Structured authoring
Consistent definitions across versions
AI will happily consume whatever you give it. The question is whether you like what it produces.
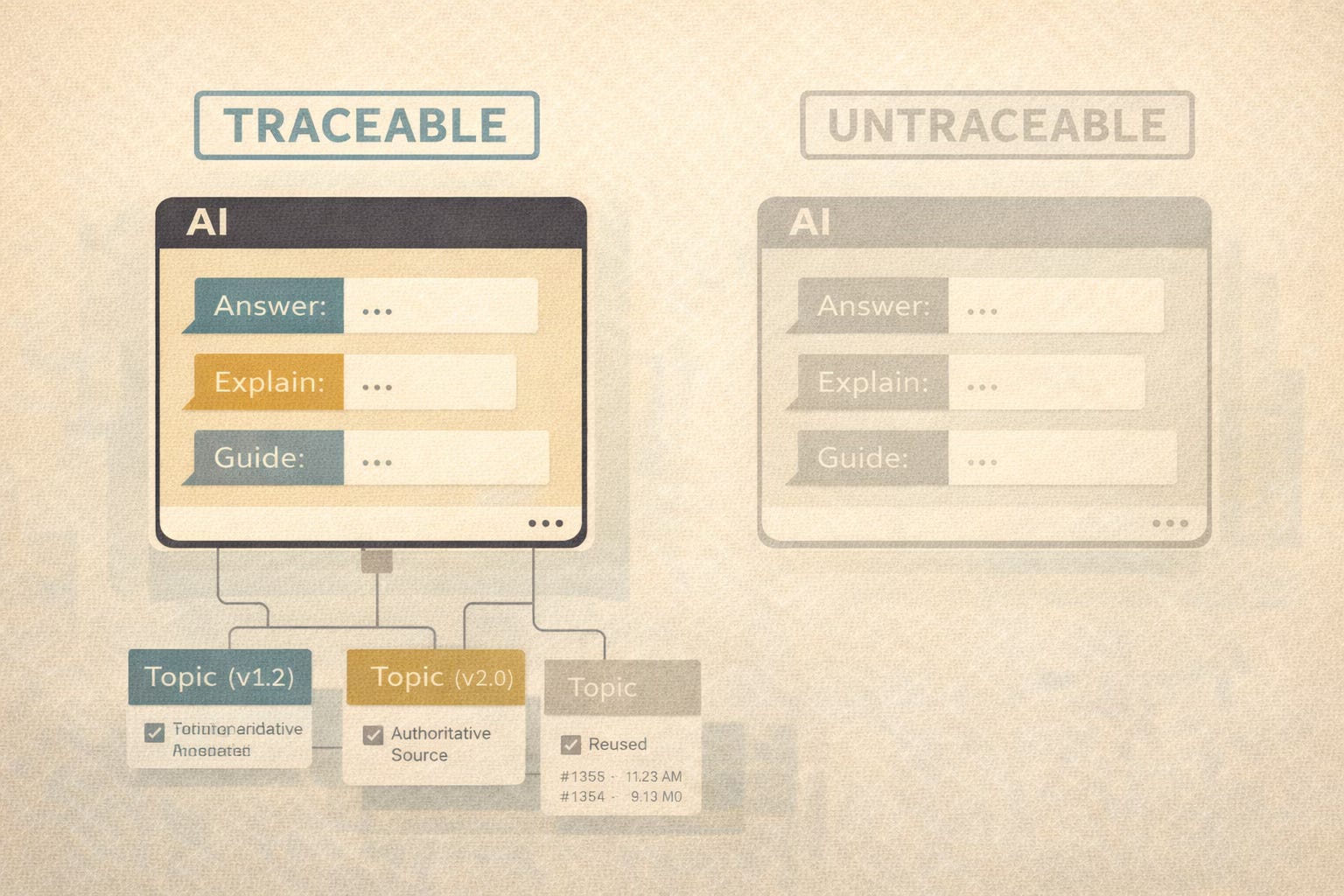
Traceability = CCMS Governance and Provenance
OG-RAG improves trust by making attribution explicit.
This maps cleanly to CCMS strengths:
versioned content
controlled reuse
authoritative sources
audit trails
When AI answers are generated from governed, versioned topics, it becomes possible to:
trace answers back to specific content
identify the source of a wrong answer
fix the documentation instead of blaming the model
This matters deeply in regulated and enterprise environments, where “trust me” 😇 is not a compliance strategy.
What This Means in Practice
If you already use DITA or a CCMS, you are not “behind” in the AI era.
You are structurally ahead—provided your system is treated as a knowledge model, not just a publishing engine.
The OG-RAG research confirms this:
AI systems do not become trustworthy because they are smarter.
They become trustworthy because the content they rely on is structured, intentional, and governed.
That work has always been the domain of technical writers.
AI is simply making it visible. 🤠
Excellent article as ever, thank you