
Google Will Teach You To Write For AI, But Not How To Keep AI From Lying
Google’s tech writing courses improve clarity and structure, but they stop short of teaching the practices needed to make AI-generated answers accurate and reliable

There’s something reassuring about Google offering free courses on tech writing. You can almost picture the outcome, right? Engineers take the course — and “Voila!” — less ambiguity; more clarity. Sentences become shorter, paragraphs stop wandering, and instructions begin to resemble actual instructions.
Their online courses walk through the fundamentals with clarity. They also include advice on working with large language models (LLMs). If you follow their guidance, your writing will likely improve. Your docs should become easier to read; your intent harder to misinterpret.
It feels like progress. And it is. But only up to a point.

The Subtle Shift No One Can Ignore
Tech docs have a new reader. Not a person skimming for answers while jumping between online meetings (and while distracted by a steady stream of Slack notifications) but a system that retrieves, assembles, and delivers those answers on demand.
The system does not read the way humans do. Instead, it predicts, reconstructs, and responds. It takes what you wrote and turns it into something else.
Google’s guidance helps us with that process. Clear sentences and logical and consistent content organization give the model something to work with. But clarity alone does not determine what the model produces.
That is where the gap begins.

When The Model Fills In The Blanks
Large language models are good at producing language that sounds correct. They’re less reliable when the source material is incomplete or inconsistent.
Unlike humans, when context is missing, the model does not pause and ask us for clarification. Instead, it proceeds full steam ahead.
Researchers at Stanford University have shown that models can generate citations that look real but do not exist. The titles and authors seem credible at first glance. The problem is the sources are fabricated, and far too often, completely detached from reality.
Other research shows that LLMs can explain what code does while missing why it was designed that way, because the reasons why weren’t captured in the docs to begin with.
Reporting from The New York Times has identified cases where AI assistants combine outdated and current info into a single answer without signaling the conflict.
These aren’t edge cases. They’re predictable outcomes. The model isn’t inventing problems. It’s exposing the gaps.
What Clear Writing Can And Cannot Do
I think Google’s guidance on clear sentences and organizing content is fairly solid.
Clarity reduces ambiguity ✅
Structure improves comprehension ✅
We know these things are required to produce usable docs. But, they’re not enough if we’re hoping they’ll help us obtain reliable AI output.
A polished sentence may still lack context. A neatly structured page may still leave out key constraints. And a clear explanation may apply only to one version, audience, or configuration without ever saying so.
LLMs do not know what we meant to include, but didn’t. It only works with what we provide it.
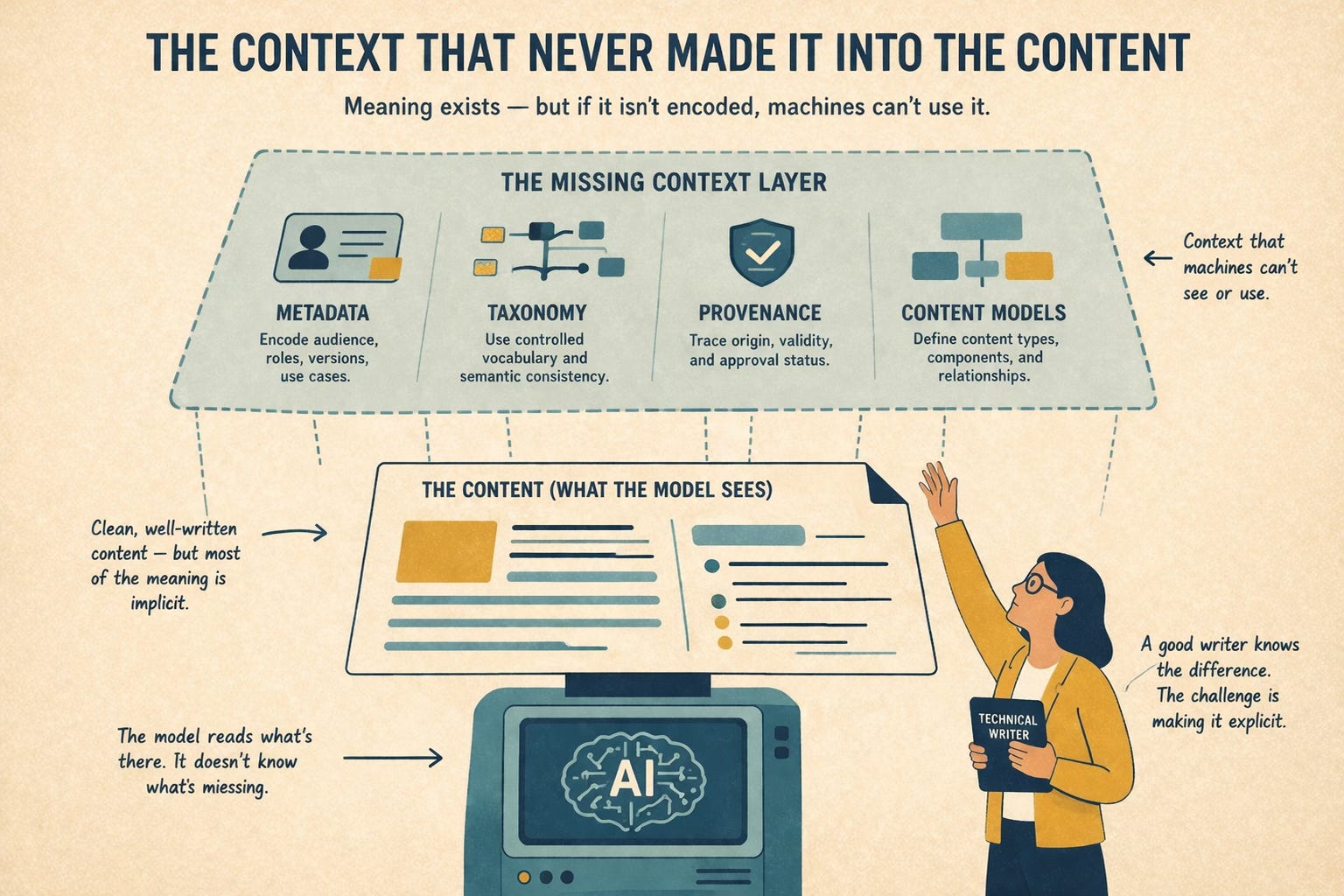
The Context That Never Made It Into The Content
This is where Google’s guidance starts to show its limits. The courses offered focus on how to write. They do not address how to encode meaning in a way machines can reliably interpret.
Consider metadata
Google tells us to define our audience, but not to encode that audience in a way that our systems can recognize and act upon.
Without metadata, important differences between user roles, product versions, and situations stay hidden. The model may blend them together into one answer that sounds correct but doesn’t really fit any of them.
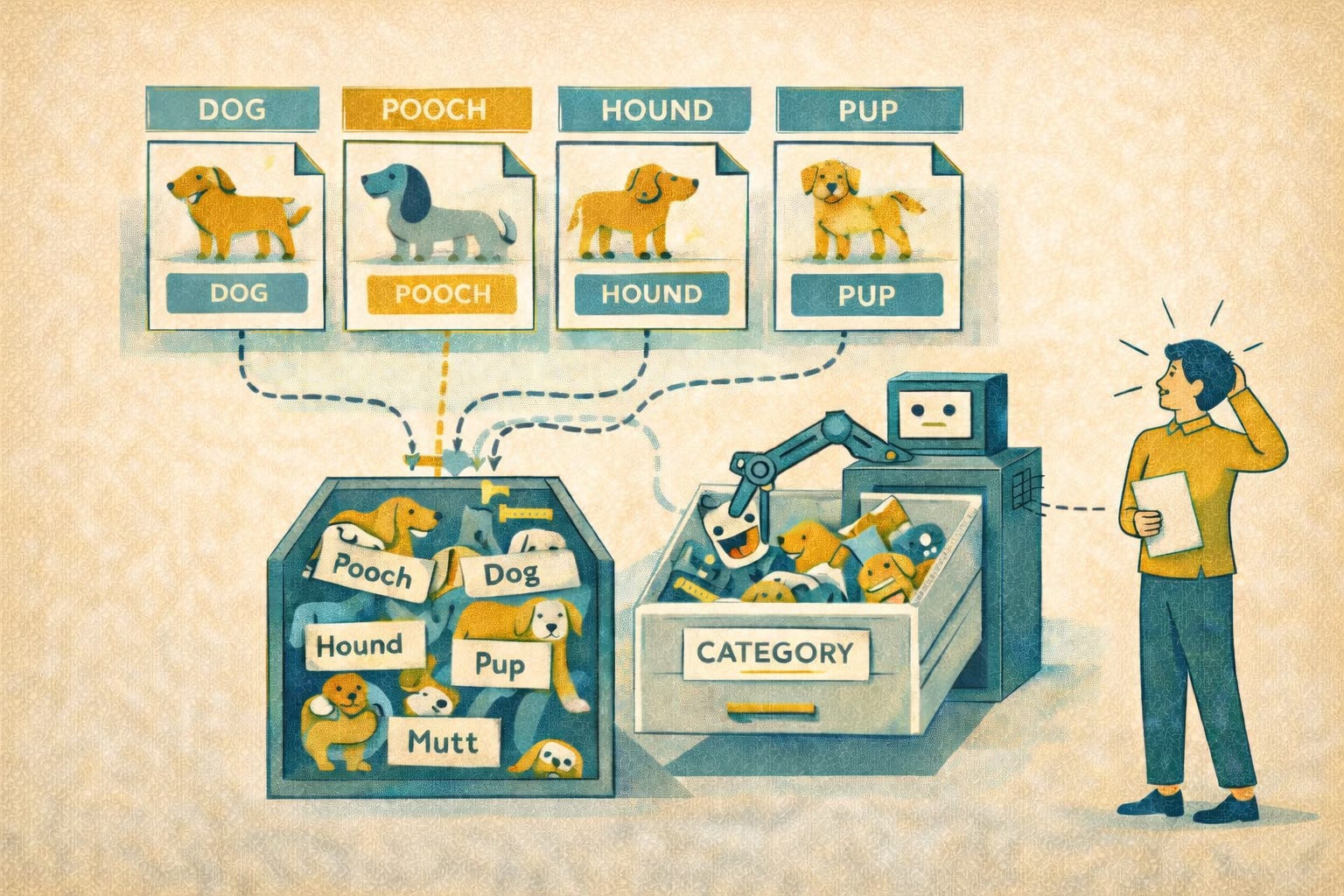
Consider taxonomy
Google encourages clear headings (a solid suggestion) but does not address controlled vocabulary or semantic consistency.
People usually know when different words are just different outfits on the same idea. Dog, pooch, hound, pup, mutt — no one needs a crisis counselor to sort that out. Context does the work.
LLMs do not always manage that trick gracefully. Sometimes they treat minor wording changes as if the universe has shifted on its axis. Other times they blur important differences and act as though related terms all belong in one big semantic junk drawer.
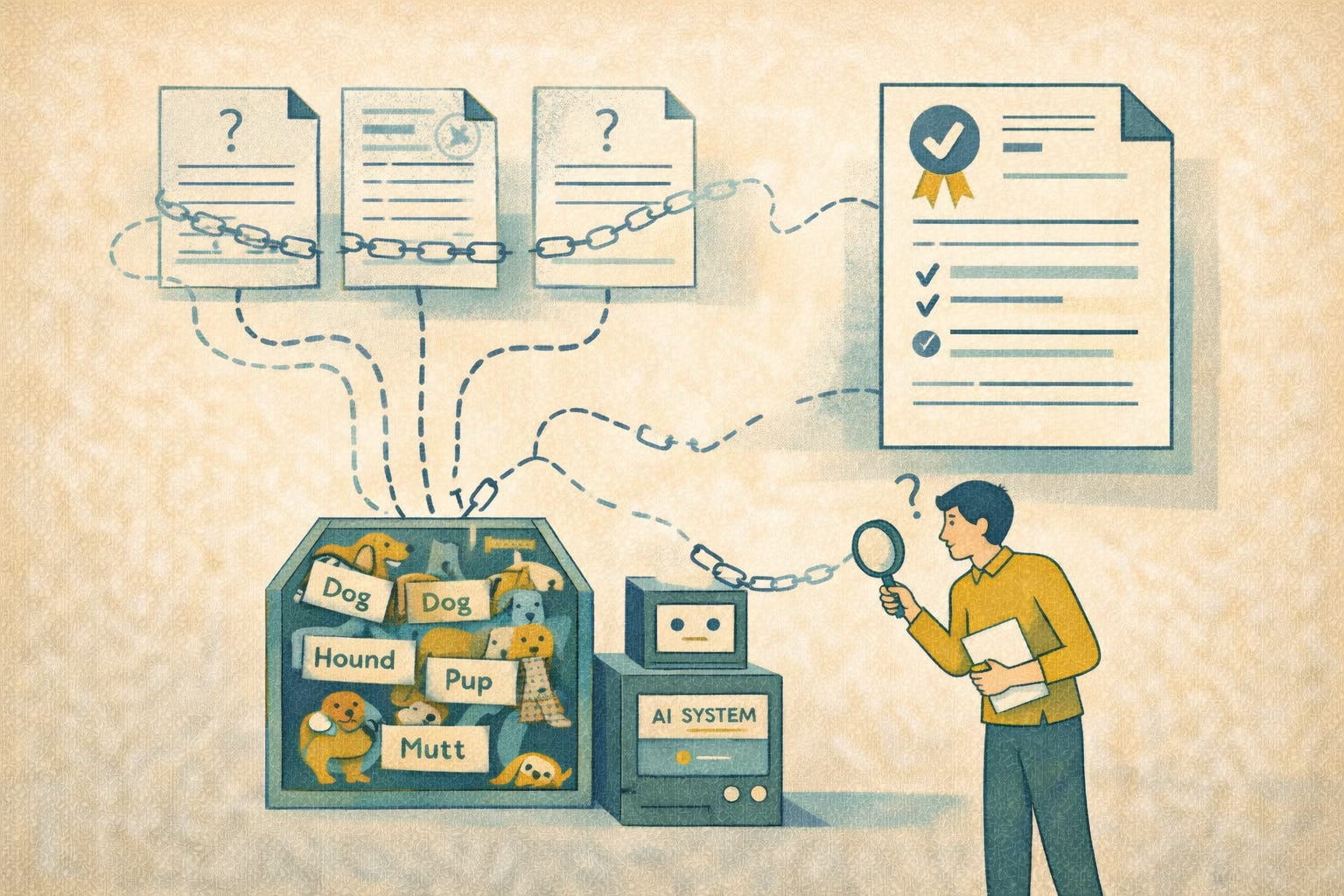
Consider provenance
Google says to review AI output, but it doesn’t explain how to check where the source content came from, whether it is still valid, or whether anyone approved it. Without that information, old or unverified content can show up next to current guidance with no warning that it may be risky.
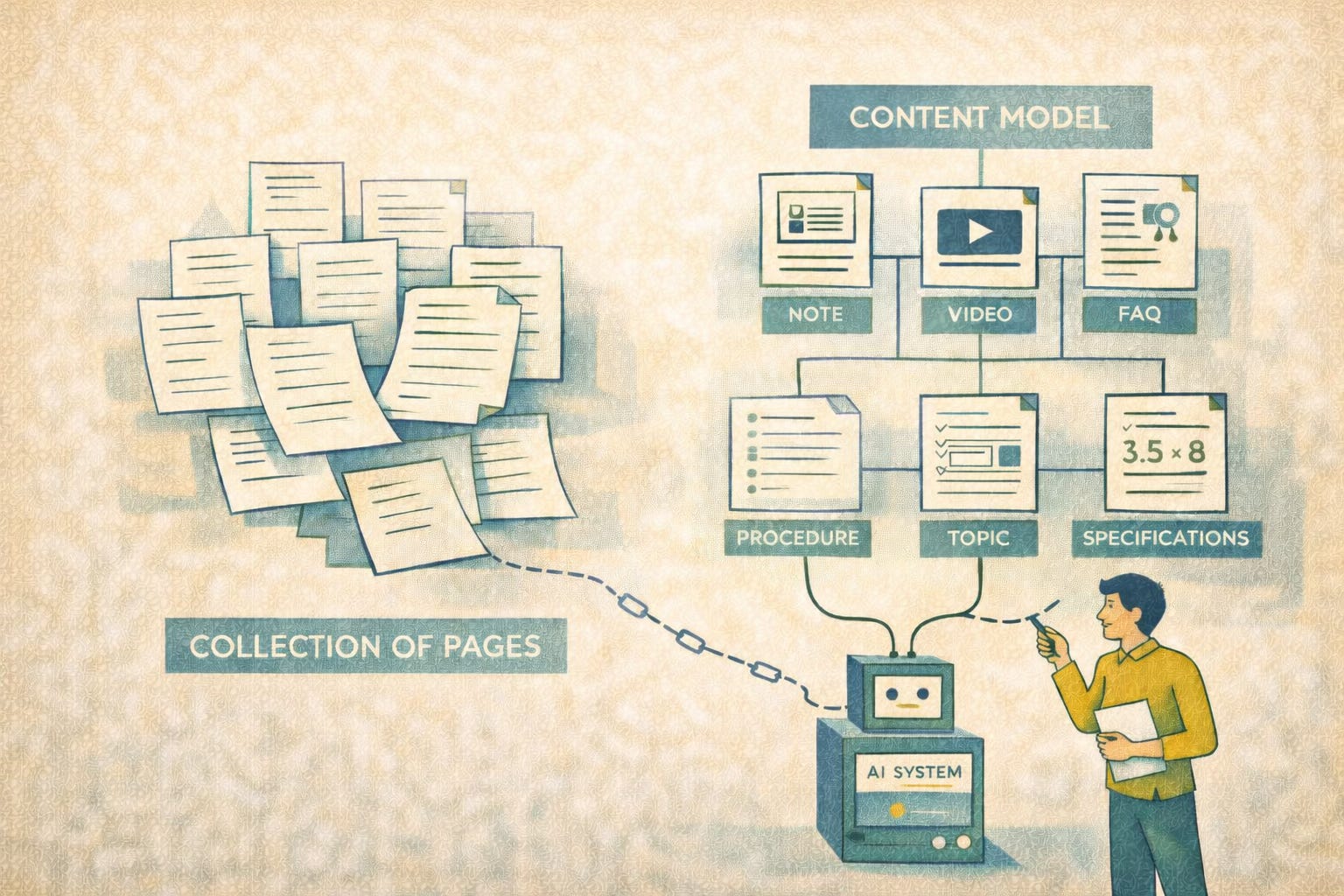
Consider content models
Google discusses organization at the document level, but not structure at the semantic level. A content model defines what types of content exist, what components they contain, and how those components relate. Without it, content remains a collection of pages. With it, content becomes a system that supports consistent interpretation.
A Familiar Scenario To Illustrate This Challenge
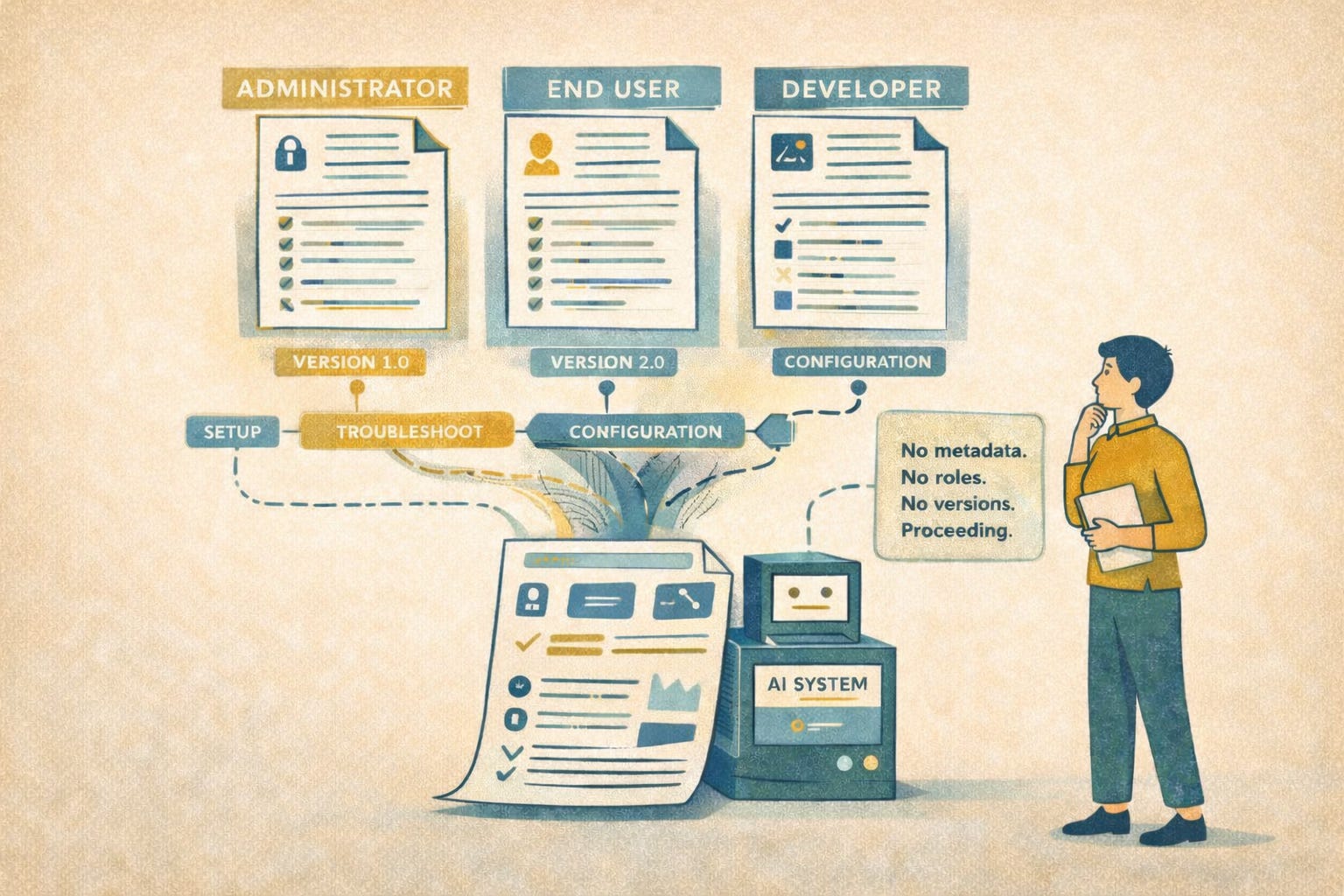
Imagine a doc set that includes a setup guide that someone wrote two years ago, a troubleshooting article you updated yesterday, and a release note explaining that the old instructions no longer work after a recent update.
Individually, each doc is clear and well written. None of them share consistent metadata, terminology, or version context.
Your user asks an AI assistant how to set up a feature. The assistant pulls info from all three documents and combines it into an answer that sounds clear and complete. But the answer is wrong for that user’s version, setup, or situation.
The problem isn’t that one document was badly written. The problem is that the content didn’t include the structure, labels, and context the AI needed to tell what applied and what didn’t.
Real-world example: [It] kept telling me that that I had to use this one envar to put the app in debug mode. But it wasn't working at all. So eventually I get around to looking deeper into it and it turns out that this method was used 2 versions prior to the current version. — GITHub post Very outdated answers and wrong suggestions everywhere
What Google Teaches Us — And What It Leaves for Us To Learn On Our Own
Google’s courses establish a baseline. They teach writers to produce content that is clear, structured, and easier to process. That baseline matters. Without it, nothing else works. Period.
But it fails to address the factors that determine whether AI-generated answers are accurate, consistent, and trustworthy. Those factors include structure beyond formatting, context beyond prose, and governance beyond editorial review.
They include decisions about how meaning is represented, how relationships are defined, and how trust is established. That work is not covered in the courses.
The Work That Now Defines Our Role
We tech writers have always been responsible for clarity. Now we’re also responsible for context. That includes making intent explicit, encoding meaning in ways machines can interpret, and ensuring that our content can be trusted when it’s retrieved, combined, and delivered outside its original form.
This isn’t a shift away from writing. It’s an expansion of what our writing must accomplish.
The sentence still matters. But the system that surrounds it matters more.
The Difference Between Readable Content And Trustworthy Content
Google will help you write docs that AI can read. It won’t help you create docs that AI can trust. And as AI takes on a larger role in delivering answers, that distinction moves from academic to operational. Those of us that recognize this distinction will design content accordingly. The rest of us will continue to wonder why their docs sound right but behave unpredictably. 🤠
This is the gap almost everyone misses.
Clear writing improves readability.
It doesn’t guarantee correctness.
LLMs don’t fail because sentences are unclear.
They fail because context is missing.
No metadata.
No versioning.
No constraints.
No structure beyond text.
So the model fills the gaps… and sounds confident doing it.
The real shift isn’t “write better”
It’s:
→ structure information
→ define context
→ build workflows that validate outputs
That’s what actually improves reliability.
Been working on mapping this into practical workflows using tools like Gemini, Docs, Sheets, and NotebookLM:
https://shorturl.at/nE0Tw