
Documentation Isn’t Dying, But Bad Production Habits Should Be Very Nervous
AI may speed drafting, but it cannot replace structured, governed content people trust and machines can interpret

Every few years, someone declares technical documentation dead with the self-assurance of a keynote speaker who has never had to explain a failed integration to an angry customer. Documentation, meanwhile, keeps stubbornly refusing to die.
👉🏾 Users still need it.
👉🏾 Support teams still depend on it. A
👉🏾 AI systems are increasingly consuming it as source material
The need hasn’t disappeared. What has changed is the environment in which documentation gets created, maintained, delivered, and now interpreted by machines. That’s the central point Ondrej Tesar (documentation lead at Pricefx) makes in a recent LinkedIn post, and it’s a useful one.
Tesar argues that AI-assisted coding is accelerating software development while doc teams risk falling behind. He points to a structural asymmetry: software teams often benefit from cleaner, more machine-friendly inputs, while documentation work still depends heavily on context gathering, judgment, and knowledge that may not be fully captured in formal systems. He also argues that the hardest part of the work lives in the undocumented remainder: tribal knowledge, edge cases, and design rationale that do not show up neatly in publicly available product information.
That argument is directionally right, but it needs one important correction.

Not All Doc Teams Are Working From A Swamp Of Vague Jira Tickets
Not all documentation teams are working from a swamp of vague Jira tickets, random Slack messages, and whatever an engineer muttered before running to another meeting. Some teams have spent years building semantically structured, metadata-rich content operations using XML, DITA, controlled vocabularies, reuse models, governed workflows, and component content management systems.
Those teams aren’t merely “writing docs.” They’re building machine-processable knowledge assets. And in a world increasingly shaped by retrieval, summarization, answer engines, agents, and large language models, that matters a great deal.
This distinction isn’t trivial. It is the whole ballgame.
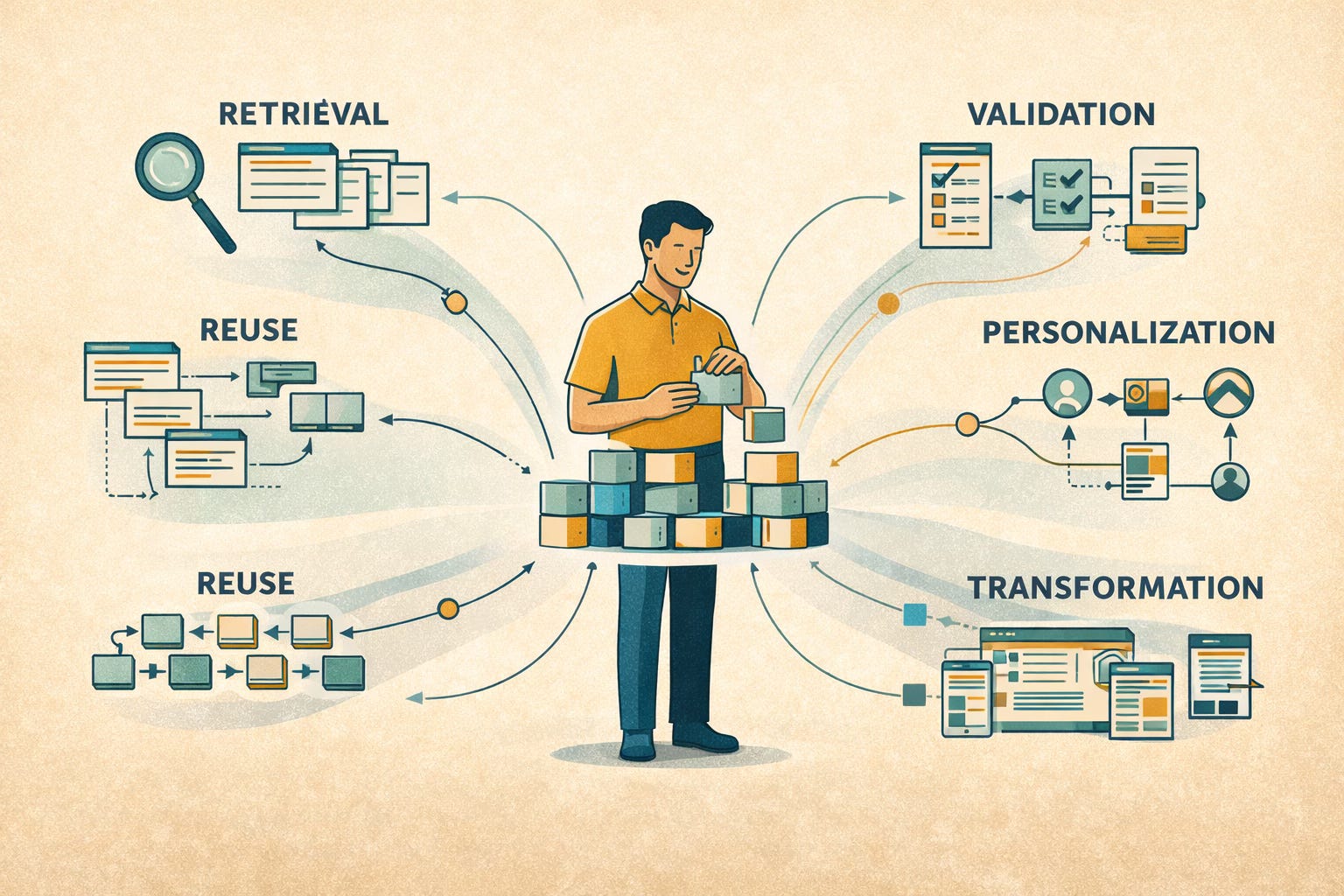
The Capability Multiplier: Semantic Structured Content
When docs are semantically structured, they become easier to retrieve, reuse, validate, govern, securely personalize, and transform. It becomes easier for both humans (and those pesky machines upon which we rely) to determine what a chunk of content is, how it relates to other chunks, when it applies, what conditions constrain it, and whether it belongs in a given output.
Structured content does not magically solve every documentation problem, but it gives us a far stronger foundation for solving them. That’s been true for years. AI just made the consequences easier for us to see.
In other words, the problem is not “documentation is inherently messy.” The problem is that too many organizations still produce documentation in immature ways, then act surprised when those methods do not scale under modern delivery pressure.

This is where Tesar’s post becomes especially useful for tech writers. He notes that writing itself is only a fraction of the job. The larger share of labor involves gathering information, reconciling contradictions, understanding audience needs, interpreting product behavior, identifying what matters, and spotting what was omitted. He cites Tom Johnson’s framing that perhaps 20 percent of the work is writing and the rest is everything surrounding it. Whether or not we agrees with the exact percentage, the broader point stands: technical communication is not a typing contest.
And this is precisely why “AI can write now” is such a flimsy managerial fantasy.
Yes siree, AI can generate paragraphs. So can Craig from marketing, and no one is proposing we let him document authentication flows unsupervised.
The hard part was never producing sentences. The hard part is producing trustworthy knowledge. That means someone must still determine what is true, what changed, what applies to which audience, what assumptions need to be made explicit, and what warnings absolutely can’t be buried three clicks deep under a cheerful heading called “Additional Notes.”
Tesar is also right to point out the validation gap. Code usually moves through a layered quality process that may include peer review, automated checks, security scans, tests, integration validation, and QA.
Documentation often gets a peer review if the stars align and someone remembers it exists before release day. Tesar’s point is not that doc teams are careless. It’s that the validation pipeline for documentation is generally less automated, less consistent, and more dependent on human judgment than the validation pipeline for code.
Again, structured content changes this equation.
Structure Makes Better QA Possible
The more structured and governed our content ecosystem is, the more we can test for consistency, completeness, reuse integrity, metadata accuracy, conditional logic, terminology compliance, and output behavior. We may not get the exact equivalent of a unit test for every paragraph, but we can move far beyond “well, Cheryl read it and said it looked fine.”
Then There’s This: AI Consuming Documentation Directly
Tesar argues that writers now need to write not only for human readers, but also for AI systems that index, retrieve, and assemble answers from docs. He recommends self-contained sections, explicit context, and semantic structure so that AI systems can interpret content correctly when surfacing it through chatbots and agents.
This is where the old “good enough” publishing mindset starts to smell like salmon left in the office microwave over the weekend. It’s not that salmon is inherently offensive. It’s that under the wrong conditions, neglected too long, it becomes a biohazard.
Unstructured or weakly governed documentation behaves the same way in AI systems.
A human reader may be able to compensate for vague headings, missing prerequisites, buried conditions, inconsistent terminology, and context scattered across six pages and a prayer. A retrieval system or LLM may maybe, probably, certainly won’t. It may reuse the wrong chunk, miss the condition that changes everything, smooth over ambiguity, and return an answer that sounds polished while being 95% wrong. That’s not an edge case; it’s a design problem.
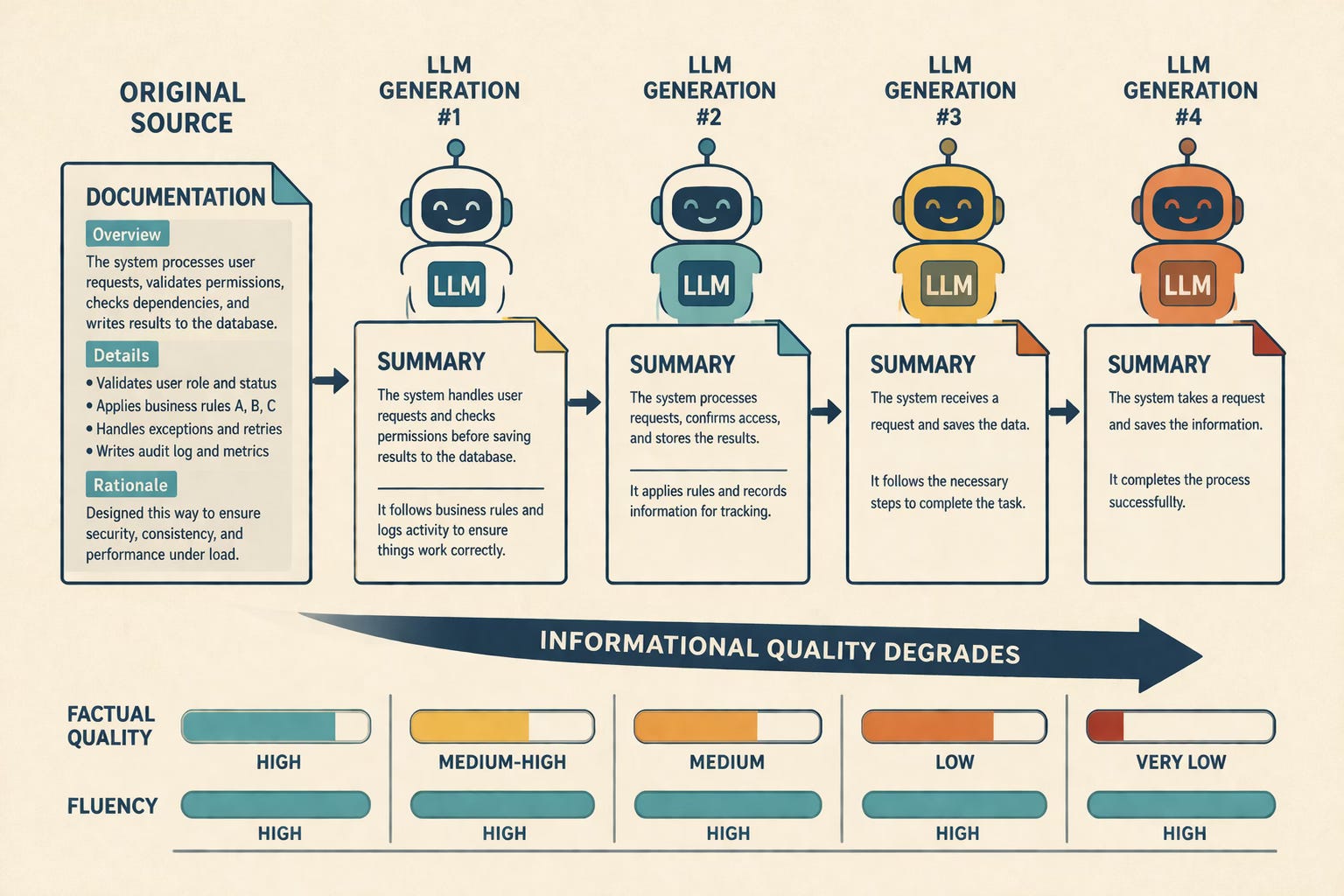
Tesar also raises a related concern: when LLM-generated content becomes source material for other LLMs, factual quality can degrade even if the language remains fluent. He cites research and commentary on how this sort of recursive training leads to model collapse, along with a study suggesting that models can explain what code does while missing why certain design decisions were made unless design documentation is provided as context.
His point is that rationale, judgment, and context don’t reliably survive abstraction unless someone captures them intentionally.
Tech writers should take that very personally. Because if docs becomes the primary knowledge layer consumed by AI systems, then structure, semantics, provenance, and governance are no longer back-office concerns. They become part of the user experience and shape whether the machine gives a useful answer, a partial answer, or a dangerously confident hallucination dressed in impeccable grammar.
That has implications for us and our managers alike.
For writers, the lesson is not “resist AI.” It is “stop acting as though sentence production is your most defensible skill.”
Let AI help with drafting, restructuring, summarizing, pattern-based content generation, and other repetitive tasks where it can provide real leverage. Tesar makes this case directly. But do not confuse that leverage with replacement. The durable value of technical communicators lies in judgment, structure, audience awareness, quality control, and the ability to turn scattered product reality into usable knowledge.
For managers, the lesson is even simpler: do not cut the documentation team because text generators exist.
Tesar explicitly argues against that move and warns that faster development without corresponding documentation capability will widen the backlog and amplify content debt. If development accelerates while docs remain under-resourced, under-tooled, and structurally immature, the result is not efficiency. It is faster delivery of confusion.
And if our docs are feeding AI-driven support, self-service, onboarding, and product guidance, that confusion will not stay politely hidden in our help center. It will be delivered directly to our users at scale.
So, Tesar is right: documentation is not dying. But the way many organizations create it is overdue for an intervention.
The future does not belong to teams that merely publish more words faster. It belongs to teams that create content machines can interpret, humans can trust, and organizations can govern. It belongs to teams that understand semantic structure is not publishing overhead. Instead, semantic structure is operational leverage. It supports interoperability, traceability, and portability. And, it makes systematic content reuse possible.
That’s been true for a long time. The difference now is that AI has made it much harder for everyone else to ignore. 🤠