
“AI Will Figure It Out” Is Not A Content Strategy
Tech writers aren’t adding unnecessary structure — they’re preventing AI from turning ambiguity into operational chaos

There’s a phrase quietly spreading through documentation teams, architecture meetings, and hallway conversations like the smell of burnt popcorn in an office microwave: “The AI can probably figure it out.”
You’ll hear this immediately after someone proposes adding content typing, metadata, role labeling, taxonomy governance, semantic structure, or any other activity requiring humans to think carefully for more than seven consecutive minutes.
Need clearer task categorization?
“The AI can infer the intent.”
Need to distinguish process explanations from procedural instructions?
“The model understands context.”
Need explicit roles, conditions, warnings, or system states?
“Modern AI is really sophisticated now.”

And there it is. The magical thinking phase of enterprise AI adoption.
Not the technical phase
Not the governance phase
Not the budgeting phase
The magical thinking phase. 🧞♂️
This is often where leaders attempt convince themselves that probability engines are somehow replacing the need for precision.
Meanwhile, tech writers are sitting in the corner like exhausted air traffic controllers wondering why everyone suddenly wants to remove the runway lights because airplanes have GPS now.
AI Does Not “Understand” Our Documentation
This is the first thing tech writers must recognize when these conversations arise.
AI systems like large language models do not understand documentation the way humans do. They don’t comprehend intention, accountability, risk, authority, or operational nuance. They predict likely relationships between patterns of words.
That distinction matters more than people realize.
When humans encounter vague instructions, they often compensate using experience, judgment, and contextual clues. We’re surprisingly good at this. We’ve had practice. Humanity has spent thousands of years decoding ambiguous instructions from bosses, governments, user manuals, and passive-aggressive family members.
AI systems compensate differently. They generate statistically plausible interpretations.
Sometimes those interpretations are correct, while other times they’re spectacularly wrong. And the more ambiguous the source material becomes, the more interpretive work the AI has to perform.
That’s not intelligence. That’s interpolation.
Ambiguity Becomes Operational Debt
For years, poorly structured documentation mostly punished humans. Our readers became frustrated. Support calls increased. New employees took longer to onboard. Procedures got skipped. Nobody enjoyed any of this, but the damage was somewhat contained.
AI changes the scale of the problem.
Now ambiguous content isn’t merely read by humans. It’s ingested, chunked, embedded, retrieved, summarized, synthesized, recombined, and operationalized by machines.
Which means every undocumented assumption suddenly matters.
If a procedure never explicitly states who performs an action, the AI has to guess
If preconditions are implied instead of stated, the AI has to infer applicability
If process explanations are mixed inside step-by-step instructions, the AI has to determine which text represents action versus explanation.
If six departments all created slightly different versions of the same procedure over eight years because governance was treated like optional cardio, the AI now retrieves conflicting truths simultaneously and attempts to merge them into one coherent answer.
What emerges is often less “artificial intelligence” and more “organizational fan fiction.”

“But The AI Can Infer Meaning” Is Missing The Point
Of course AI can infer meaning. Humans can infer meaning too. That’s not the benchmark.
The real question is this:
Why are we designing enterprise knowledge systems that require inference in the first place?
Especially when the content could’ve been explicit.
This is where tech writers need to reposition the conversation. The goal of structured content isn’t to make documents prettier, more academic, or more technically fashionable. The goal is to reduce ambiguity before ambiguity becomes automation.
Because once AI systems start generating answers from our content ecosystem, every vague sentence becomes a liability multiplier.

The Difference Between Retrieval And Guessing
Consider this instruction:
“Access the admin panel and update the system configuration.”
Simple enough, right?
Except now our AI system has to determine:
Who can perform this action?
Under what conditions?
Is this a required task or optional guidance?
What happens afterward?
What permissions are required?
What risks exist?
Is this production-safe?
Is this procedural instruction or conceptual explanation?
Now compare that with content explicitly structured as:
Task
Role
Preconditions
Procedure
Expected outcome
Warnings
Exceptions
Suddenly the AI isn’t “understanding” better. It’s guessing less.
That’s the entire game.
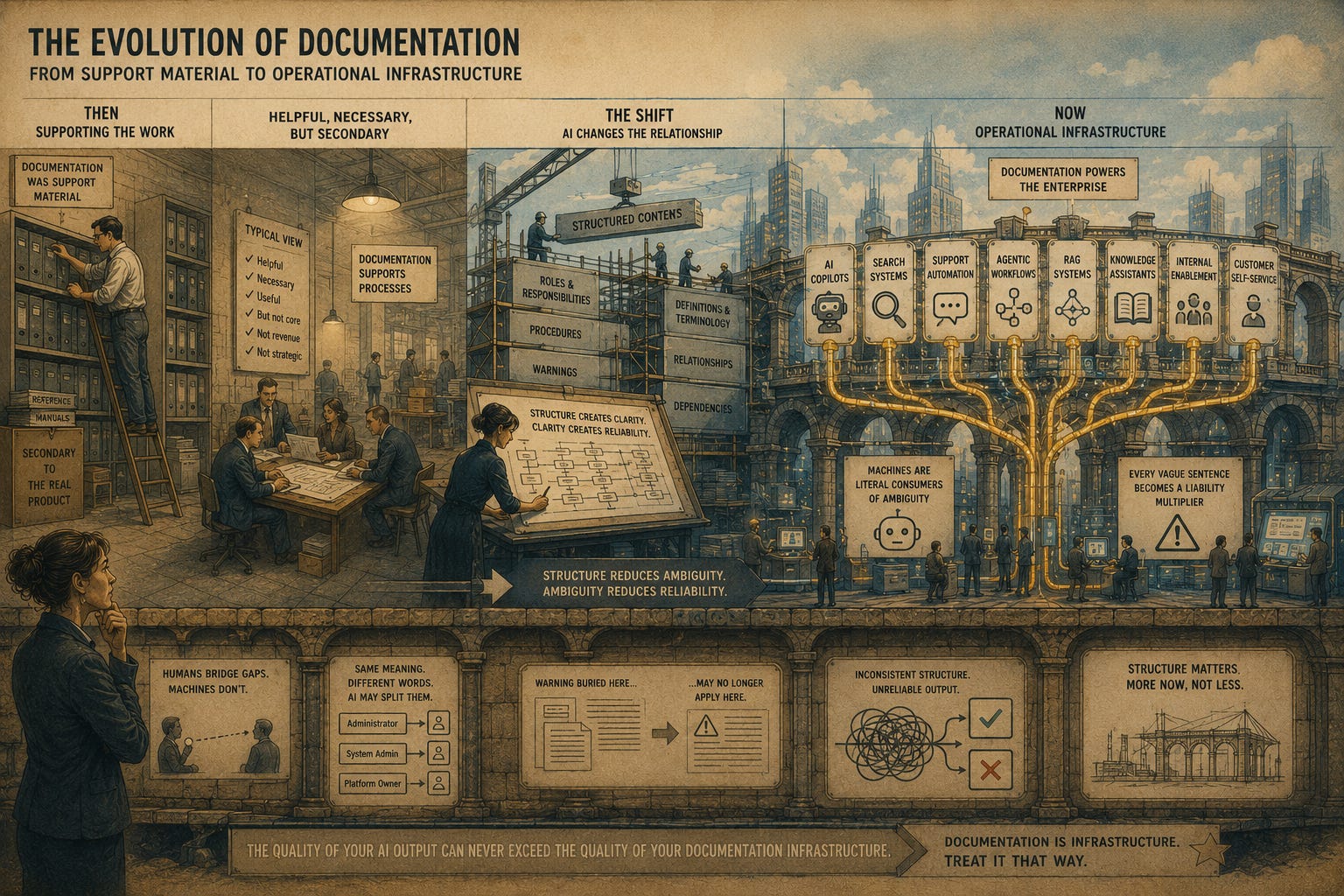
AI Has Quietly Turned Technical Documentation Into Infrastructure
This is the shift many organizations still haven’t absorbed. Docs used to be viewed as support material. Helpful, certainly. Necessary, perhaps. But still secondary to “the real product.”
AI changes that relationship.
Technical documentation is now operational infrastructure.
It feeds:
AI copilots
Search systems
Support automation
Agentic workflows
Retrieval-augmented generation (RAG) systems
Knowledge assistants
Internal enablement systems
Customer self-service platforms
Machine are now one of our primary readers. And they’re remarkably literal consumers of ambiguity.
Humans might recognize that two procedures are “basically the same.” AI systems may interpret them as separate truths. Humans might notice that “administrator,” “system admin,” and “platform owner” refer to the same role. AI systems may not.
Humans recognize that a warning ⚠️ buried four paragraphs later still applies to the earlier step. AI systems may sever that relationship entirely during retrieval.
This is why structure matters more now, not less.
Even Structured Content Can Fail AI
This part makes some people uncomfortable.
Simply having XML isn’t enough. Our docs can be perfectly valid structured content (well-formed and that conforms to a specific structure (think Darwin Information Typing Architecture or DITA) and still fail AI retrieval scenarios because the semantics of our docs are weak, incomplete, or inconsistent.
👉🏼 A task topic missing actor clarity is ambiguous
👉🏼 A process explanation embedded inside procedural steps can easily create confusion
👉🏼 A role implied through prose rather than explicitly identified forces inference
This is partly why semantic approaches like PREA — Process, Role, Event, Actor — become increasingly valuable in AI environments. They help us explicitly expose operational relationships that prose alone often obscures.
What Tech Writers Should Say When SMEs Push Back
This is where diplomacy matters.
If we frame structured content as bureaucracy, we’ll lose. But, if we frame structured content as operational risk reduction, scalability, reuse enablement, and AI reliability, people start listening.
The conversation shifts from:
“Why are you making authoring more complicated?”
to:
“How do we reduce AI misinterpretation at scale?”
That’s a very different meeting. And frankly, a much more interesting one.
The Real Irony Of Our AI-Powered Work
The rise of AI is not reducing the value of disciplined technical communication. Instead, it’s exposing how badly organizations needed it all along.
For years, weak structure, inconsistent terminology, duplicated procedures, and vague ownership models survived because our readers compensated for our content chaos manually.
AI removes that safety net.
Suddenly organizations are discovering that “kind of organized” is not a machine-readable strategy. Who could’ve guessed.
Well, probably the tech writers. 🤠
Scott, thank you for articulating this so clearly. You’re absolutely right: “AI will figure it out” is not a content strategy. And authors can only reduce ambiguity when they’re enabled, not just instructed.
In many organizations, authors are handed tools and “processes” that look good on paper but are empty of meaning. They are instructed, but not enabled. They’re asked what they want, even though they’ve never been shown what they need. Upstream and downstream are invisible. Everyone works with blinkers on.
Clarity must begin much earlier than most organizations realize. A concept needs to be named at birth, and its meaning must be maintained throughout the entire terminology lifecycle. Without this, everything downstream — UI labels, product labels, documentation, localization, content delivery, and even AI — becomes unstable.
This is why shared terminology and language as an enterprise wide Single Source of Truth is essential. A terminology and knowledge management system, embedded in an ecosystem of tools that all draw from the same meaning, gives everyone a common foundation.
And that common understanding is not only for AI. It’s for humans — especially the many people in the content creation workflow who are not native speakers of the language they work in: product designers, engineers, authors, SMEs. They often produce grammatically correct text that still doesn’t convey the intended meaning. Rules alone don’t help them. They need language patterns, examples, and guidance that show what “good” looks like.
Navigation is another area where alignment matters. UI text is terminology, and so are the labels printed on physical products. If the UI says one thing, the product label says another, and the documentation uses a third term, users cannot navigate — not the interface, not the machine, not the instructions. Proper labeling and consistent terminology across UI, product, and documentation are essential for safe, successful navigation.
Localization is also a critical feedback loop. No one reads content as closely as translators do. They are the experts in detecting ambiguity, missing concepts, inconsistent labels, and unclear intent — because they must reconstruct meaning in another language. Their questions are not noise; they are knowledge assets that should flow back into terminology, controlled language, and content design.
And then there are the terminology scenarios that organizations often overlook:
• third party documentation shipped with integrated systems
• legacy terminology from older product generations
• terminology inherited after mergers and acquisitions
• terminology imposed by standards and regulations (e.g., EC Declaration of Conformity)
These scenarios introduce conflicting terms, conflicting meanings, and conflicting constraints. Without governance, they fragment the user experience and confuse both humans and AI.
When terminology is governed at the source and supported by patterns, examples, and feedback, everything aligns more naturally:
• naming decisions before UI and product labels diverge
• controlled language that supports both humans and AI
• structured content grounded in governed meaning
• localization that strengthens the system instead of patching it
• content delivery that becomes findable and searchable
• concept tagging that makes content reusable and AI ready
• navigation that works because labels match across product, UI, and documentation
• terminology scenarios managed instead of ignored
When people understand the whole semantic ecosystem, they stop guessing. They start creating clarity — for humans and for AI.
And the encouraging part is: you don’t need to fix everything at once.
Start with one concept. Start with one naming decision. Start with one lookup. Start with one aligned label. Start with one empowered author.
Clarity grows from small, repeatable actions. Enablement turns those actions into a habit. That’s how organizations become truly AI ready — and human ready.
Noelani Walker Koser
Hi,
Love your content on AI! I'm Sia from Novita AI—we help developers access and deploy LLMs instantly, without the hassle of managing infrastructure themselves.
We're currently building our creator network through an affiliate program. Your followers are exactly the kind of developers and builders who benefit from our service, and I think this could be a valuable opportunity for you.
Happy to share details if you're interested.
Best,
Sia